Nick Bostrom writes about “information hazards”, or “infohazards”:
Information hazards are risks that arise from the dissemination or the potential dissemination of true information that may cause harm or enable some agent to cause harm. Such hazards are often subtler than direct physical threats, and, as a consequence, are easily overlooked. They can, however, be important. This paper surveys the terrain and proposes a taxonomy.
The paper considers both cases of (a) the information causing harm directly, and (b) the information enabling some agent to cause harm.
The main point I want to make is: cases of information being harmful are easier to construct when different agents’ interests/optimization are misaligned; when agents’ interests are aligned, infohazards still exist, but they’re weirder edge cases. Therefore, “infohazard” being an important concept is Bayesian evidence for misalignment of interests/optimizations, which would be better-modeled by conflict theory than mistake theory.
Most of the infohazard types in Bostrom’s paper involve conflict and/or significant misalignment between different agents’ interests:
1. Data hazard: followed by discussion of a malicious user of technology (adversarial)
2. Idea hazard: also followed by discussion of a malicious user of technology (adversarial)
3. Attention hazard: followed by a discussion including the word “adversary” (adversarial)
4. Template hazard: follows discussion of competing firms copying each other (adversarial)
5. Signaling hazard: follows discussion of people avoiding revealing their properties to others, followed by discussion of crackpots squeezing out legitimate research (adversarial)
6. Evocation hazard: follows discussion of activation of psychological processes through presentation (ambiguously adversarial, non-VNM)
7. Enemy hazard: by definition adversarial
8. Competitiveness hazard: by definition adversarial
9. Intellectual property hazard: by definition adversarial
10. Commitment hazard: follows discussion of commitments in adversarial situations (adversarial)
11. Knowing-too-much hazard: followed by discussion of political suppression of information (adversarial)
12. Norm hazard: followed by discussion of driving on sides of road, corruption, and money (includes adversarial situations)
13. Information asymmetry hazard: followed by discussion of “market for lemons” (adversarial)
14. Unveiling hazard: followed by discussion of iterated prisoner’s dilemma (misalignment of agents’ interests)
15. Recognition hazard: followed by discussion of avoiding common knowledge about a fart (non-VNM, non-adversarial, ambiguous whether this is a problem on net)
16. Ideological hazard: followed by discussion of true-but-misleading information resulting from someone starting with irrational beliefs (non-VNM, non-adversarial, not a strong argument against generally spreading information)
17. Distraction and temptation hazards: followed by discussion of TV watching (non-VNM, though superstimuli are ambiguously adversarial)
18. Role model hazard: followed by discussion of copycat suicides (non-VNM, non-adversarial, ambiguous whether this is a problem on net)
19. Biasing hazard: followed by discussion of double-blind experiments (non-VNM, non-adversarial)
20. De-biasing hazard: follows discussion of individual biases helping society (misalignment of agents’ interests)
21. Neuropsychological hazard: followed by discussion of limitations of memory architecture (non-VNM, non-adversarial)
22. Information-burying hazard: follows discussion of irrelevant information making relevant information harder to find (non-adversarial, though uncompelling as an argument against sharing relevant information)
23. Psychological reaction hazard: follows discussion of people being disappointed (non-VNM, non-adversarial)
24. Belief-constituted value hazard: defined as a psychological issue (non-VNM, non-adversarial)
25. Disappointment hazard: subset of psychological reaction hazard (non-VNM, non-adversarial, ambiguous whether this is a problem on net)
26. Spoiler hazard: followed by discussion of movies and TV being less fun when the outcome is known (non-VNM, non-adversarial, ambiguous whether this is a problem on net)
27. Mindset hazard: followed by discussion of cynicism and atrophy of spirit (non-VNM, non-adversarial, ambiguous whether this is a problem on net)
28. Embarrassment hazard: followed by discussion of self-image and competition between firms (non-VNM, includes adversarial situations)
29. Information system hazard: follows discussion of viruses and other inputs to programs that cause malfunctioning (includes adversarial situations)
30. Information infrastructure failure hazard: definition mentions cyber attacks (adversarial)
31. Information infrastructure misuse hazard: follows discussion of Stalin reading emails, followed by discussion of unintentional misuse (includes adversarial situations)
32. Robot hazard: followed by discussion of a robot programmed to launch missiles under some circumstances (includes adversarial situations)
33. Artificial intelligence hazard: followed by discussion of AI outcompeting and manipulating humans (includes adversarial situations)
Of these 33 types, 12 are unambiguously adversarial, 5 include adversarial situations, 2 are ambiguously adversarial, and 2 include significant misalignment of interests between different agents. The remaining 12 generally involve non-VNM behavior, although there is one case (information-burying hazard) where the agent in question might be a utility maximizer (though, this type of hazard is not an argument against sharing relevant information). I have tagged multiple of these as “ambiguous whether this is a problem on net”, to indicate the lack of a strong argument that the information in question (e.g. disappointing information) is actually bad for the receiver on net.
Simply counting examples in the paper isn’t a particularly strong argument, however. Perhaps the examples have been picked through a biased process. Here I’ll present some theoretical arguments.
There is a standard argument that the value of information is non-negative, that every rational agent from its own perspective cannot expect to be harmed by learning anything. I will present this argument here.
Let’s say the actual state of the world is 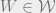
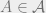
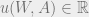
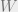
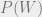
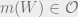

Now, the question is, can the agent achieve lower utility in expectation if they learn 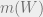
Assume the agent doesn’t learn 
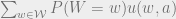

On the other hand, suppose the agent learns 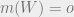
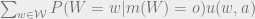
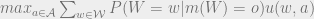
Under uncertainty about
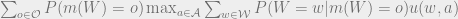
Due to convexity of the 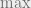
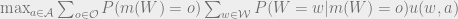
Re-arranging the summation and applying the definition of conditional probability, this is equal to:

Marginalizing over 
But this is the same as the utility achieved without learning
(Note that this argument is compatible with the agent getting lower utility 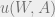
Is it possible to construct a multi-agent problem, where the agents have the same utility function, and they are all harmed by some of them learning something? Suppose Alice and Bob are deciding on a coffee shop to meet without being able to communicate beforehand, by finding a Schelling point. The only nearby coffee shop they know about is Carol’s. Derek also owns a coffee shop which is nearby. Derek has the option of telling Alice and Bob about his coffee shop (and how good it is); they can’t contact him or each other, but they can still receive his message (e.g. because he advertises it on a billboard).
If Alice and Bob don’t know about Derek’s coffee shop, they successfully meet at Carol’s coffee shop with high probability. But, if they learn about Derek’s coffee shop, they may find it hard to decide which one to go to, and therefore fail to meet at the same one. (I have made the point previously that about-equally-good options can raise problems in coordination games).
This result is interesting because it’s a case of agents with the same goal (meeting at a good coffee shop) accomplishing that goal worse by knowing something than by not knowing it. There are some problems with this example, however. For one, Derek’s coffee shop may be significantly better than Carol’s, in which case Derek informing both Alice and Bob leads to them both meeting at Derek’s coffee shop, which is better than Carol’s. If Derek’s coffee shop is significantly worse, then Derek informing Alice and Bob does not impact their ability to meet at Carol’s coffee shop. So Derek could only predictably make their utility worse if somehow he knew that his shop was about as good to them as Carol’s. But then it could be argued that, by remaining silent, Derek is sending Alice and Bob a signal that his coffee shop is about as good, since he would not have remained silent in other cases.
So even when I try to come up with a case of infohazards among cooperative agents, the example has problems. Perhaps other people are better than me at coming up with such examples. (While Bostrom presents examples of information hazards among agents with aligned interests in the paper, these lack enough mathematical detail to formally analyze them with utility theory to the degree that the coffee shop example can be analyzed.)
It is also possible that utility theory is substantially false, that humans don’t really “have utility functions” and therefore there can be information hazards. Bostrom’s paper presents multiple examples of non-VNM behavior in humans. This would call for revision of utility theory in general, which is a project beyond the scope of this post.
It is, in contrast, trivial to come up with examples of information hazards in competitive games. Suppose Alice and Bob are playing Starcraft. Alice is creating lots of some unit (say, zerglings). Alice could tell Bob about this. If Bob knew this, he would be able to prepare for an attack by this unit. This would be bad for Alice’s ability to win the game.
It is still the case that Bob gains higher expected utility by knowing about Alice’s zerglings, which makes it somewhat strange to call this an “information hazard”; it’s more natural to say that Alice is benefitting from an information asymmetry. Since she’s playing a zero-sum game with Bob, anything that increases Bob’s (local) utility function, including having more information and options, decreases Alice’s (local) utility function. It is, therefore, unsurprising that the original “value of information is non-negative” argument can be turned on its head to show that “your opponent having information is bad for you”.
There are, of course, games other than common-payoff games and zero-sum games, which could also contain cases of some agent being harmed by another agent having information.
It is, here, useful to distinguish the broad sense of “infohazard” that Bostrom uses, which includes multi-agent situations, from a narrower sense of “self-infohazards”, in which a given individual gains a lower utility by knowing something. The value-of-information argument presented at the start shows that there are no self-infohazards in an ideal game-theoretic case. Cooperative situations, such as the coffee shop example, aren’t exactly cases of a self-infohazard (which would violate the original value-of-information theorem), although there is a similarity in that we could consider Alice and Bob as parts of a single agent given that they have the same local utility function. The original value of information argument doesn’t quite apply to these (which allows the coffee shop example to be constructed), but almost does, which is why the example is such an edge case.
Some apparent cases of self-infohazards are actually cases where it is bad for some agent A to be believed by some agent B to know some fact X. For example, the example Bostrom gives of political oppression of people knowing some fact is a case of the harm to the knower coming not from their own knowledge, but from others’ knowledge of their knowledge.
The Sequences contain quite a significant amount of advice to ignore the idea that information might be bad for you, to learn the truth anyway: the Litany of Tarski, the Litany of Gendlin, “that which can be destroyed by the truth should be”. This seems like basically good advice even if there are some edge-case exceptions; until coming up with a better policy than “always be willing to learn true relevant information”, making exceptions risks ending up in a simulacrum with no way out.
A case of some agent A denying information to some agent B with the claim that it is to agent B’s benefit is, at the very least, suspicious. As I’ve argued, self-infohazards are impossible in the ideal utility theoretic case. To the extent that human behavior and values deviate from utility theory, such cases could be constructed. Even if such cases exist, however, it is hard for agent B to distinguish this case from one where agent A’s interests and/or optimization are misaligned with B’s, so that the denial of information is about maintaining an information asymmetry that advantages A over B.
Sociologically, it is common in “cult” situations for the leader(s) to deny information to the followers, often with the idea that it is to the followers’ benefit, that they are not yet ready for this information. Such esotericism allows the leaders to maintain an information asymmetry over the followers, increasing their degree of control. The followers may trust the leaders to really be withholding only the information that would be harmful to them. But this is a very high degree of trust. It makes the leaders effectively unaccountable, since they are withholding the information that could be used to evaluate their claims, including the claim that withholding the information is good for the followers. The leaders, correspondingly, take on quite a high degree of responsibility for the followers’ lives, like a zookeeper takes on responsibility for the zoo animals’ lives; given that the followers don’t have important information, they are unable to make good decisions when such decisions depend on this information.
It is common in a Christian context for priests to refer to their followers as a “flock”, a herd of people being managed and contained, partially through information asymmetry: use of very selective readings of the Bible, without disclaimers about the poor historical evidence for the stories’ truth (despite priests’ own knowledge of Biblical criticism), to moralize about ways of life. It is, likewise, common for parents to lie to children partially to “maintain their innocence”, in a context where the parents have quite a lot of control over the childrens’ lives, as their guardians. My point here isn’t that this is always bad for those denied information (although I think it is in the usual case), but that it requires a high degree of trust and requires the information-denier to take on responsibility for making decisions that the one denied information is effectively unable to make due to the information disadvantage.
The Garden of Eden is a mythological story of a self-infohazard: learning about good and evil makes Eve and Adam less able to be happy animals, more controlled by shame. It is, to a significant degree, a rigged situation, since it is set up by Yahweh. Eve’s evaluation, that learning information will be to her benefit, is, as argued, true in most cases; she would have to extend quite a lot of trust to her captor to believe that she should avoid information that would be needed to escape from the zoo. In this case her captor is, by construction, Yahweh, so a sentimentally pro-Yahweh version of the story shows mostly negative consequences from this choice. (There are also, of course, sentimentally anti-Yahweh interpretations of the story, in Satanism and Gnosticism, which consider Eve’s decision to learn about good and evil to be wise.)
Situations that are explicitly low-trust usually don’t use the concept of a self-infohazard. In a corporate setting, it’s normal to think that it’s good for your own company to have more information, but potentially bad for other companies to have information such as trade secrets or information that could be used to make legal threats. The goal of corporate espionage isn’t to spread information to opponents while avoiding learning information about them, it’s to learn about the opponents while preventing them from learning about your company, which may include actively misleading them by presenting them with false or misleading information. The harms of receiving misleading information are mitigated, not by not gathering information in the first place, but by gathering enough information to cross-check and build a more complete picture.
The closest corporate case I know of to belief in self-infohazards is in a large tech company which has a policy of not allowing engineers to read the GDPR privacy law; instead, their policy is to have lawyers read the law, and give engineers guidelines for “complying with the law”. The main reason for this is that following the law literally as stated would not be possible while still providing the desired service. Engineers, who are more literal-minded than lawyers, are more likely to be hindered by knowing the literal content of the law than they are if they receive easier guidelines from lawyers. This is still somewhat of an edge case, since information isn’t being denied to the engineers for their own sake so much as so the company can claim to not be knowingly violating the law; given the potential for employees to be called to the witness stand, denying information to employees can protect the company as a whole. So it is still, indirectly, a case of denying information to potential adversaries (such as prosecutors).
In a legal setting, there are cases where information is denied to people, e.g. evidence is considered inadmissible due to police not following procedure in gaining that information. This information is not denied to the jury primarily because it would be bad for the jury; rather, it’s denied to them because it would be unfair to one side in the case (such as the defendant), and because admitting such information would create bad incentives for information-gatherers such as police detectives, which is bad for information-gatherers who are following procedure; it would also increase executive power, likely at the expense of the common people.
So, invocation of the notion of a self-infohazard is Bayesian evidence, not just of a conflict situation, but of a concealed conflict situation, where outsiders are more likely than insiders to label the situation as a conflict, e.g. in a cult.
It is important to keep in mind that, for A to have information they claim to be denying to B for B’s benefit, A must have at some point decided to learn this information. I have rarely, if ever, heard cases where A, upon learning the information, actively regrets it; rather, their choice to learn about it shows that they expected such learning to be good for them, and this expectation is usually agreed with later. I infer that it is common for A to be applying a different standard to B than to A; to consider B weaker, more in need of protection, and less agentic than A.
To quote @jd_pressman on Twitter:
Empathy based ethics in a darwinian organism often boils down to “Positive utilitarianism for me, negative utilitarianism for thee.”
Different standards are often applied because the situation actually is more of a conflict situation than is being explicitly represented. One applies to one’s self a standard that values positively one’s agency, information, capacity, and existence, and one applies to others a standard that values negatively their agency, information, capacity, and existence; such differential application increases one’s position in the conflict (e.g. evolutionary competition) relative to others. This can, of course, be rhetorically justified in various ways by appealing to the idea that the other would “suffer” by having greater capacities, or would “not be able to handle it” and is “in need of protection”. These rhetorical justifications aren’t always false, but they are suspicious in light of the considerations presented.
Nick Bostrom, for example, despite discussing “disappointment risks”, spends quite a lot of his time thinking about very disappointing scenarios, such as AGI killing everyone, or nuclear war happening. This shows a revealed preference for, not against, receiving disappointing information.
An important cultural property of the word “infohazard” is that it is used quite differently in a responsible/serious and a casual/playful context. In a responsible/serious context, the concept is used to invoke the idea that terrible consequences, such as the entire world being destroyed, could result from people talking openly about certain topics, justifying centralization of information in a small inner ring. In a casual/playful context, “infohazard” means something other people don’t want you to know, something exciting the way occult and/or Eldritch concepts are exciting, something you could use to gain an advantage over others, something delicious.
Here are a few Twitter examples:
- “i subsist on a diet consisting mostly of infohazards” (link)
- “maintain a steady infohazard diet like those animals that eat poisonous plants, so that your mind will poison those that try to eat it” (link)
- “oooooh an information hazard… Googling, thanks” (link)
- “are you mature/cool enough to handle the infohazard that a lot of conversations about infohazards are driven more by games around who is mature/cool enough than by actual reasoned concern about info & hazards?” (link)
The idea that you could come up with an idea that harms people in weird ways when they learn about it is, in a certain light, totally awesome, the way mind control powers are awesome, or the way being an advanced magical user (wizard/witch/warlock/etc) is awesome. The idea is fun the way the SCP wiki is fun (especially the parts about antimemetics).
It is understandable that this sort of value inversion would come from an oppositional attitude to “responsible” misinforming of others, as a form of reverse psychology that is closely related to the Streisand effect. Under a conflict theory, someone not wanting you to know something is evidence for it being good for you to learn!
This can all still be true even if there are some actual examples of self-infohazards, due to non-VNM values or behavior in humans. However, given the argument I am making, the more important the “infohazard” concept is considered, the more evidence there is of a possibly-concealed conflict; continuing to apply a mistake theory to the situation becomes harder and harder, in a Bayesian sense, as this information (about people encouraging each other not to accumulate more information) accumulates.
As a fictional example, the movie They Live (1988) depicts a situation in which aliens have taken over and are ruling Earth. The protagonist acquires sunglasses that show him the ways aliens control himself and others. He attempts to put the sunglasses on his friend, to show him the political situation; however, his friend physically tries to fight off this attempt, treating the information revealed by the sunglasses as a self-infohazard. This is in large part because, by seeing the concealed conflict, the friend could be uncomfortably forced to modify his statements and actions accordingly, such as by picking sides.
The movie Bird Box (2018) is a popular and evocative depiction of a self-infohazard (similar in many ways to Langford’s basilisk), in the form of a monster that, when viewed, causes the viewer to die with high probability, and to with low probability become a “psycho” who tries to show the monster to everyone else forcefully. The main characters use blindfolds and other tactics to avoid viewing the monster. There was a critical discussion of this movie that argued that the monster represents racism. The protagonists, who are mostly white (although there is a black man who is literally an uncle named “Tom”), avoid seeing inter-group conflict; such a strategy only works for people with a certain kind of “privilege”, who don’t need to directly see the conflict to navigate daily life. Such an interpretation of the movie is in line with the invocation of “infohazards” being Bayesian evidence of concealed conflicts.
What is one to do if one feels like something might be an “infohazard” but is convinced by this argument that there is likely some concealed conflict? An obvious step is to model the conflict, as I did in the case of the tech company “complying” with GDPR by denying engineers information. Such a multi-agent model makes it clear why it may be in some agents’ interest for some agents (themselves or others) to be denied information. It also makes it clearer that there are generally losers, not just winners, when information is hidden, and makes it clearer who those losers are.
There is a saying about adversarial situations such as poker games: “If you look around the table and you can’t tell who the sucker is, it’s you”. If you’re in a conflict situation (which the “infohazard” concept is Bayesian evidence for), and you don’t know who is losing by information being concealed, that’s Bayesian evidence that you are someone who is harmed by this concealment; those who are tracking the conflict situation, by knowing who the losers are, are more likely to ensure that they end up ahead.
As a corollary of the above (reframing “loser” as “adversary”): if you’re worried about information spreading because someone might be motivated to use it to do something bad for you, knowing who that someone is and the properties of them and their situation allows you to better minimize the costs and maximize the benefits of spreading or concealing information, e.g. by writing the information in such a way that some audiences are more likely than others to read it and consider it important.
Maybe the “infohazard” situation you’re thinking about really isn’t a concealed conflict and it’s actually a violation of VNM utility; in that case, the consideration to make clear is how and why VNM doesn’t apply to the situation. Such a consideration would be a critique of Bayesian/utility based models applying to humans of the sort studied by the field of behavioral economics. I expect that people will often be biased towards looking for exceptions to VNM rather than looking for concealed conflicts (as they are, by assumption, concealing the conflict); however, that doesn’t mean that such exceptions literally never occur.

I see infohazards for students all the time: situations where it is best for the student not to know the answer, and to attempt to figure it out for themselves.
Another non-adversarial info hazard is cross-validation (you have to hold out data from the training set, lest you overfit).
Both have an adversarial flavor, but I think the deeper commonality is that they’re fundamentally non-Bayesian. In the first case, there’s “something to figure out” because the student doesn’t immediately know all consequences of their beliefs. In the second, because CV is, well, non-Bayesian by definition.
LikeLiked by 2 people
Thanks for commenting, I agree that this is a good example of an infohazard.
LikeLike
\max_{a \in \mathcal{A}} \sum_{o \in \mathcal{O}} \sum_{w \in \mathcal{O}} P(m(W)=o \wedge W = w)u(w, a). should be \max_{a \in \mathcal{A}} \sum_{o \in \mathcal{O}} \sum_{w \in \mathcal{W}} P(m(W)=o \wedge W = w)u(w, a).
LikeLike
Fixed, thanks.
LikeLiked by 1 person