The Sleeping Beauty problem is a famous philosophical puzzle. Described by Elga (2000):
Some researchers are going to put you to sleep. During the two days that your sleep will last, they will briefly wake you up either once or twice, depending on the toss of a fair coin (Heads: once; Tails: twice). After each waking, they will put you back to sleep with a drug that makes you forget that waking. When you are first awakened, to what degree ought you believe that the outcome of the coin toss is Heads?
Stipulate that Beauty (“you”) wakes only on Monday if Heads, and on Monday and Tuesday if Tails. The standard answers are 1/3 and 1/2 for the probability of Heads. Among those who answer 1/2, we ask a follow-up question: “When you are awakened and then learn it is Monday, to what degree ought you believe that the outcome of the coin is Heads?”. The standard answers are 2/3 and 1/2. Of those who endorsed 1/2 for the original question, those who answer 2/3 to this follow-up question are “single halfers”, and those who answer 1/2 to this follow-up question are “double halfers”. Generally, people who answer 1/3 to the original question answer 1/2 to the follow-up question, and are called “thirders”.
In anthropic theory, SSA (self-sampling assumption) generalizes single-halfing, SIA (self-indication assumption) generalizes thirding, and FNC (full non-indexical conditioning) generalizes double-halfing. (Where relevant, I assume self-sampling over observer moments, in line with Bostrom’s “SSSA”, to handle cases of amnesia.) To summarize these theories:
- A SSA agent assigs probabilities as if it is sampled randomly from all observers in the universe who are in its reference class. (Reference class is a parameter SSA needs, but SIA and FNC don’t.)
- A SIA agent first multiplies its prior probabilities over universes by the universe’s number of observers, then (as in SSA) conditions on itself being a random sample from observers in a universe sampled according to this modified prior, and that observer having its observation.
- A FNC agent conditions its prior over universes on “some observer with my observation exists” to get its distribution over universes. (Optionally, one can add a self-sampling assumption among agents in this universe with this specific observation, though Radford Neal, author of FNC, believes it goes better without such indexical self-sampling.)
One complication: In practice, FNC will agree with thirding in the Sleeping Beauty problem, because Beauty receives random data upon waking up, and the specific random observation sequence is more likely to exist conditional on Tails, because there are more chances for the sequence to happen. FNC endorses double-halfing in a controlled scenario where Beauty is a brain upload and has the exact same information state upon waking up regardless of Heads+Monday, Tails+Monday, or Tails+Tuesday, and regardless of random data that would vary between runs of the scenario. Charitably to double-halfing, I assume this controlled Sleeping Beauty scenario for the purposes of this post.
I explore Dutch book arguments against anthropic theories in the context of Sleeping Beauty. A Dutch book against an agent is a sequence of bets they are offered which leads to a sure loss for them, if they bet according to their probabilities, and linear utility in how much money they end up with. My Dutch books satisfy two strict criteria: (a) the bookie must have no information not had by the agent at the time the bet takes place; (b) the agent’s probabilities must strictly favor the sure-loss sequence of bets if they assign probabilities according to the theory; theories with ambiguity about probabilities can resist Dutch books.
I will focus mainly on CDT, since CDT agents accept or reject bets straightforwardly according to their betting odds. First, I present simple Dutch book arguments against CDT single-halfing and CDT double-halfing. Second, I argue that CDT thirding is resistant to Dutch books. Third, I discuss EDT.
Dutch booking CDT single-halfers
This Dutch book offers one bet on Sunday, and one on Monday. It doesn’t matter if the coin has already been flipped by the time of the bet on Sunday, provided the bookie does not know the result. Beauty only considers the Monday bet after knowing it is Monday.
The Sunday bet is as follows: “-$14 if Heads, +$16 if Tails”. A CDT single-halfer accepts, because Heads and Tails are equally likely; the expected value is 1/2(-$14 + $16) = $1.
The Monday bet is as follows: “+$11 if Heads, -$19 if Tails”. A CDT single-halfer accepts, because they assign 2/3 to Heads once they see it is Monday; the expected value is 2/3 * $11 + 1/3 * -$19 = $1.
If the coin is Heads, then the overall payoff is -$14 + $11 = -$3. If the coin is Tails, then the overall payoff is $16 – $19 = -$3. This is a sure loss.
(For prior work on Dutch books for CDT single-halfers, see Hitchcock 2004 and Draper and Pust 2008; see Briggs 2010 on CDT/EDT divergence.)
Dutch booking CDT double-halfers
This Dutch book offers two bets. Bet A is offered when Beauty has woken up, and otherwise has no posterior information; we imagine the bookie is woken up and administered amnesia drugs just like Beauty. Upon Tails, bet A is offered twice; we label the Monday A-bet as AM, and the Tuesday A-bet as AT. Bet B is offered on Monday after Beauty has accepted or rejected bet AM, and has been told the day (we imagine the bookie learns the day at the same time as Beauty, and only offers bet B if it is Monday). Importantly, no bets are offered prior to Monday.
Bet A is as follows: “+$10 if Heads; -$8 if Tails”. The CDT double-halfer accepts, because they assign 50% Heads; the expected value is 1/2 * ($10 – $8) = $1.
Bet B is as follows: “-$11 if Heads; +$15 if Tails”. The CDT double-halfer accepts, because they assign 1/2 to Heads and 1/2 to Tails upon learning it is Monday; the expected value is 1/2 * (-$11 + $15) = $2.
If the coin is Heads, the CDT double-halfer accepts bets AM and B; the overall payoff is $10 – $11 = -$1. If the coin is Tails, then CDT double-halfer accepts bets AM, B, and AT; the overall payoff is -$8 + $15 – $8 = -$1. This is a sure loss.
(Hitchcock’s 2004 Dutch book also applies to double-halfers, but requires a bet to happen before any awakening, unlike this section’s Dutch book. “Anthropics: Full Non-indexical Conditioning (FNC) is inconsistent” (Armstrong 2019) notes diachronic inconsistency of FNC, which this Dutch book exploits.)
CDT thirders resist Dutch books
To make a positive case for thirding, we examine ex ante optimality arguments for CDT+SIA (which generalizes betting according to thirding odds). A policy is ex ante optimal when it is expected to attain maximal expected utility if adopted ahead of time. “Can rational choice guide us to correct de se beliefs?” (Conitzer 2015) supports CDT+SIA ex ante optimality in additive games. Additive games do not require Beauty to “worry about coordinating her actions with her selves from other awakenings”, and include ordinary imperfect-recall betting scenarios. CDT+SIA is ex ante optimal for additive games: “when we restrict our attention to additive games, then a thirder will necessarily maximize her ex ante expected payout, but a halfer in some cases will not (assuming causal decision theory)”.
In the other direction, all ex ante optimal policies are compatible with CDT+SIA in a wide class of imperfect-recall scenarios, a superset of additive games. See my “In memoryless Cartesian environments, every UDT policy is a CDT+SIA policy” (2016) and prior work (“On the Interpretation of Decision Problems with Imperfect Recall”, Piccione and Rubinstein, 1997, Proposition 3: “If a behavioral strategy is optimal then it is modified multiself consistent”).
Together, these considerations show that CDT+SIA policies are exactly ex ante optimal policies in additive games. Therefore, there are no Dutch books against CDT+SIA in additive games, and even in non-additive games (of the class studied in Piccione 1997), there are ex ante optimal (therefore non-Dutch-bookable) policies compatible with CDT+SIA.
“A Dutch Book for CDT thirders” (Korzukhin 2020) presents a non-additive game where CDT+SIA can lose; the scenario does not meet my strict condition (b). Quoting the paper: “if we allow Sleeping Beauty to deliberate dynamically, she will end up in one of two possible stable states: she may converge on rejecting, or she may converge on accepting.” Indeed, not every CDT+SIA policy is ex ante optimal in non-additive games. Still, this failure mode pales in comparison to those of CDT+SSA and CDT+FNC, which compel ex ante suboptimal policies even in additive games (such as the situations of the above Dutch books).
EDT and Dutch books
The Dutch book against CDT single-halfers also works against EDT single-halfers, because the Monday bet is only considered once Beauty is certain that it is Monday. Similar considerations have been noted in the literature; “the reasoning utilized by the evidential decision theorist to evade Hitchcock’s [diachronic Dutch book] cannot be employed here” (Draper and Pust 2008).
A draft paper (“Can de se choice be ex ante reasonable in games of imperfect recall? A complete analysis”, Oesterheld and Conitzer, 2024) claims CDT+SSA, EDT+SSA, EDT+SIA, CDT+FNC are all Dutch bookable, but that EDT+FNC is compatible with ex ante optimality (and accordingly resistant to Dutch books). This post supports Dutch books for CDT+SSA, CDT+FNC, and EDT+SSA, though I have not checked all claims in the draft paper. I will briefly examine EDT+FNC on this post’s Dutch book for double-halfers.
An EDT+FNC agent will, when offered bet A, use FNC to assign probability 50% to Heads, and 50% to Tails; Oesterheld et al. add indexical self-sampling so “Tails and Monday” equally probable with “Tails and Tuesday” (both 25%), though this is not decision-theoretically important. To simplify, we first suppose bet B is not offered. The agent believes its general policy of whether to accept bet A is uncorrelated with Heads/Tails. Using EDT, the agent estimates that, conditional on accepting bet A as a general policy, the expected payoff is 1/2 * $10 + 1/2 * (-$8 + -$8) = -$3, whereas the expected payoff is $0 conditional on rejecting bet A as a general policy. And the agent’s action is good evidence about its general policy for what it does in this very information state. So the agent rejects bet A, and adding bet B into the mix does not change this.
The main upshot is that EDT’s betting behavior differs from naively betting according to posterior anthropic probabilities, unlike CDT, which matches naive betting behavior. As such, traditional Dutch book analysis must be modified when considering EDT agents. EDT+FNC avoids this post’s Dutch book against double-halfers, but only by agreeing with CDT+SIA about which bets to accept.
Intuitively, an EDT+FNC agent acts as if it considers the consequences of its information state’s action, rather than its body’s action. Upon being offered bet A, an EDT+FNC agent can reason that its information state would exist either way the coin went (so its existence tells it nothing about the coin), but that its information state has one embodied occurrence if Heads and two embodied occurrences if Tails; the reason to reject bet A is that the bet’s consequences are doubled in the Tails case due to two embodied occurrences each accepting an episode of bet A.
“A Dutch book against sleeping beauties who are evidential decision theorists” (Conitzer 2015) argues that EDT is subject to Dutch books in Sleeping Beauty variants due to correlations between actions taken in different information states. Oesterheld and Conitzer (2024) address this by specifying that in their version of EDT, “For all other 



Conclusion
Decision-theoretic considerations support betting according to CDT+SIA, and against betting according to CDT+SSA and CDT+FNC. How much does this support thirding in Sleeping Beauty, at a philosophical level?
First, philosophical problems with SSA (and therefore single-halfing) are well-known; see Bostrom’s Paradoxes of the Self-Sampling Assumption. CDT+SSA and EDT+SSA are easily Dutch booked. An important general problem for combining SSA with decision theory is that adding “dummies” (copies of the agent, who receive an observation informing them they are a dummy, and whose actions don’t matter) to a situation changes SSA’s posterior probabilities (given non-dummy observations), and by default this change causes decision-theoretic problems, since dummy counts do not affect ex ante strategy optimality.
Second, while CDT+FNC is easily Dutch booked, EDT+FNC is a serious contender, by the analysis of Oesterheld and Conitzer (2024), though this analysis relies on independence assumptions. Of course, FNC ‘thirds’ in realistic Sleeping Beauty scenarios (due to random observations), but double-halves in controlled brain upload versions. FNC is non-Bayesian, which is why this post’s Dutch book against CDT double-halfers succeeds, even without needing any pre-experimental bets: the update between bet AM and bet B (from learning it is Monday) is non-Bayesian. Standard Dutch book arguments for Bayesian updating would apply under CDT, but EDT agents bet at odds not matching their subjective probabilities.
I prefer CDT+SIA to EDT+FNC since it is more theoretically elegant, has more concordance with standard theories of probability such as Bayesianism, and has ex ante optimality results (especially for additive games) that do not depend on strong independence assumptions. Still, EDT+FNC appears to be the strongest alternative anthropic decision theory at the moment, and I don’t have a decisive argument against it.
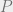 is an intrinsic property of a concrete object,
is an intrinsic property of a concrete object,  , is
, is  , and each of these is
, and each of these is  .
. which is reliably correlated with objective redness (crudely, ~700nm light emission, but better specified than that). Philosophers of w’ argue for an epistemic gap between
which is reliably correlated with objective redness (crudely, ~700nm light emission, but better specified than that). Philosophers of w’ argue for an epistemic gap between  (a refinement of “~450nm light emission”) going along with redness.
(a refinement of “~450nm light emission”) going along with redness.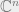 .
.
 . Its state is best thought of as also including its velocity
. Its state is best thought of as also including its velocity  . Note that
. Note that  has constant magnitude, corresponding to conservation of energy. Now over time, the normalized
has constant magnitude, corresponding to conservation of energy. Now over time, the normalized 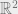 point moves in a circle. Phase-translating the system would imply cyclical movement through phase space; a full cycle happens in time
point moves in a circle. Phase-translating the system would imply cyclical movement through phase space; a full cycle happens in time  . A complex scalar specifies both how to phase-translate a phasor, and how to scale it (here, scaling would apply to both position and velocity). By representing the phasor
. A complex scalar specifies both how to phase-translate a phasor, and how to scale it (here, scaling would apply to both position and velocity). By representing the phasor  , multiplying by a complex scalar will phase-translate and scale. Here, multiplying by i represents moving forward a quarter of one cycle, though in other representations, –i would do so instead. The phasor is inherently more symmetric than the scalar; which phase to consider “1” in this complex representation, and whether multiplication by i steps time forwards or backwards, are fairly arbitrary.
, multiplying by a complex scalar will phase-translate and scale. Here, multiplying by i represents moving forward a quarter of one cycle, though in other representations, –i would do so instead. The phasor is inherently more symmetric than the scalar; which phase to consider “1” in this complex representation, and whether multiplication by i steps time forwards or backwards, are fairly arbitrary.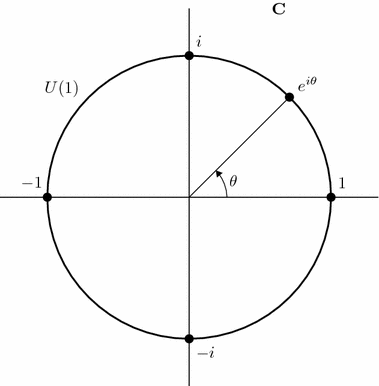
 the non-zero complex numbers, considered as a group under multiplication. An element of the group can be thought of as a combined positive scaling and phase translation. Let
the non-zero complex numbers, considered as a group under multiplication. An element of the group can be thought of as a combined positive scaling and phase translation. Let  be the sub-group of
be the sub-group of  be the positive reals considered as a group under multiplication. Now the decomposition
be the positive reals considered as a group under multiplication. Now the decomposition  holds: multiplication by a non-zero complex number combines scaling and phase translation.
holds: multiplication by a non-zero complex number combines scaling and phase translation.
 ), and one morphism per element of G. A convenient notation for the category of
), and one morphism per element of G. A convenient notation for the category of  .
. (
( ) satisfying
) satisfying  and
and  . We now have a set of elements that can be scaled and phase-translated. Hence, S conceptually represents a set of phasors (or multi-phasors), which are acted on by complex scalars.
. We now have a set of elements that can be scaled and phase-translated. Hence, S conceptually represents a set of phasors (or multi-phasors), which are acted on by complex scalars.
 is equivariant iff
is equivariant iff  for all
for all  . This is looking a lot like linearity, though we do not have zero or addition. To handle additivity, it will help to factor out the
. This is looking a lot like linearity, though we do not have zero or addition. To handle additivity, it will help to factor out the  semimodules (to model negation as action by
semimodules (to model negation as action by  ), real vector spaces are mathematically nicer. Let
), real vector spaces are mathematically nicer. Let  be the category of real vector spaces and linear maps between them.
be the category of real vector spaces and linear maps between them.![[BU(1), \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BBU%281%29%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . Each element is a real vector space with a U(1) action. We can write the action as
. Each element is a real vector space with a U(1) action. We can write the action as  for complex unitary a. Note
for complex unitary a. Note  is linear for fixed a.
is linear for fixed a. is U(1)-equivariant iff
is U(1)-equivariant iff  for all complex unitary a.
for all complex unitary a. for
for  , which is valid for ideal harmonic oscillators, and of course relevant to destructive interference. We now extend S to a complex vector space, defining scalar multiplication as
, which is valid for ideal harmonic oscillators, and of course relevant to destructive interference. We now extend S to a complex vector space, defining scalar multiplication as  for real a, b. This is a standard
for real a, b. This is a standard  . The assumption of opposite-phase cancellation is therefore the only distinction between a U(1)-symmetric real vector space in
. The assumption of opposite-phase cancellation is therefore the only distinction between a U(1)-symmetric real vector space in ![[BU, \mathsf{Vect}_\mathbb{R}]](https://s0.wp.com/latex.php?latex=%5BBU%2C+%5Cmathsf%7BVect%7D_%5Cmathbb%7BR%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) and a proper complex vector space.
and a proper complex vector space.
 , where SO(2) is the set of rotations in Euclidean space. This of course relates to visualizing phase translation as rotation, and seeing phasors as moving in a circle. While SO(2) gives 2D rotational symmetries of a circle, it does not give all symmetries of a circle. That would be the
, where SO(2) is the set of rotations in Euclidean space. This of course relates to visualizing phase translation as rotation, and seeing phasors as moving in a circle. While SO(2) gives 2D rotational symmetries of a circle, it does not give all symmetries of a circle. That would be the 
 for complex unitary a, meant to represent a phase translation, and J, meant to represent a distinguished mirroring. We have the following algebraic identities:
for complex unitary a, meant to represent a phase translation, and J, meant to represent a distinguished mirroring. We have the following algebraic identities:


 is an inverse. We can derive that
is an inverse. We can derive that  , so mirroring reverses the way phase translations go, as expected.
, so mirroring reverses the way phase translations go, as expected.![[BO(2), \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BBO%282%29%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , noting the previous correspondence with complex vector spaces, motivates the following definition. A
, noting the previous correspondence with complex vector spaces, motivates the following definition. A  that is an antilinear involution, i.e.:
that is an antilinear involution, i.e.:
 for complex
for complex 

 has a real structure
has a real structure  . So the involution
. So the involution  generalizes complex conjugate.
generalizes complex conjugate.
 , then a linear map
, then a linear map  for all
for all 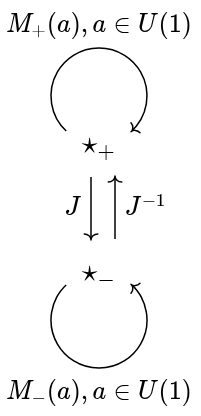
 , which has two objects
, which has two objects  . For complex unitary a, we have morphisms
. For complex unitary a, we have morphisms  and
and  , which compose and invert as usual for U(1). We also have an isomorphism
, which compose and invert as usual for U(1). We also have an isomorphism  satisfying
satisfying  .
.  ). The only essential difference is in separating the two connected components of O(2) into separate objects of the groupoid
). The only essential difference is in separating the two connected components of O(2) into separate objects of the groupoid ![[U(1)_{\pm}, \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BU%281%29_%7B%5Cpm%7D%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . An object of this category picks out two U(1)-symmetric real vector spaces (of which complex vector spaces are an important class), and provides a real-linear isomorphism between them corresponding to J; this isomorphism is not, in general, complex-linear. Importantly, the groupoidal identity
. An object of this category picks out two U(1)-symmetric real vector spaces (of which complex vector spaces are an important class), and provides a real-linear isomorphism between them corresponding to J; this isomorphism is not, in general, complex-linear. Importantly, the groupoidal identity  be a complex vector space with the same elements as V and the same addition function. The only difference is that scalar multiplication is conjugated;
be a complex vector space with the same elements as V and the same addition function. The only difference is that scalar multiplication is conjugated;  . We call
. We call 
 , we write
, we write  for the corresponding vector in the complex conjugate space. Note the following:
for the corresponding vector in the complex conjugate space. Note the following:

 for complex
for complex 
 notation here is not entirely standard (although
notation here is not entirely standard (although  looks like
looks like  , and they are in fact equal.
, and they are in fact equal. as
as  . This definition matches what we would expect from morphisms (natural transformations) in
. This definition matches what we would expect from morphisms (natural transformations) in ![[U(1)_\pm, \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BU%281%29_%5Cpm%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . By treating f and
. By treating f and  as separate functions, we avoid the rigidity of σ-linearity.
as separate functions, we avoid the rigidity of σ-linearity. , where
, where 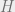 is a Hilbert space (or other complex inner product space). While the inner product is linear in its second argument, it is notoriously anti-linear in its first argument. So while on the one hand
is a Hilbert space (or other complex inner product space). While the inner product is linear in its second argument, it is notoriously anti-linear in its first argument. So while on the one hand  , on the other hand,
, on the other hand,  . Also, the inner product is conjugate symmetric:
. Also, the inner product is conjugate symmetric:  .
. be a quantum state. Now the inner product
be a quantum state. Now the inner product  gives the square of the norm of the state
gives the square of the norm of the state  , as a non-negative real number. If the inner product were bilinear, then we would have
, as a non-negative real number. If the inner product were bilinear, then we would have  . But multiplying
. But multiplying  as expected.
as expected. . The complex conjugate space
. The complex conjugate space  . And we recover conjugate symmetry as
. And we recover conjugate symmetry as  ; the overlines make the conjugate symmetry more intuitive, as we can see parity of conjugation is preserved.
; the overlines make the conjugate symmetry more intuitive, as we can see parity of conjugation is preserved. as a linear map
as a linear map  ; for the inner product, this corresponding map is
; for the inner product, this corresponding map is  . This correspondence motivates studying the complex vector space
. This correspondence motivates studying the complex vector space  .
. . To check:
. To check:
 .
. is notation for a vector in the Hilbert space H. A ‘bra’
is notation for a vector in the Hilbert space H. A ‘bra’  is an element of the dual space of linear functionals of the form
is an element of the dual space of linear functionals of the form  ; this dual space is called
; this dual space is called  . We convert between bras and kets as follows. Given a ket
. We convert between bras and kets as follows. Given a ket  , the corresponding bra is
, the corresponding bra is  , which linearly maps kets to complex numbers. The ket-to-bra mapping is invertible, and antilinear, due to
, which linearly maps kets to complex numbers. The ket-to-bra mapping is invertible, and antilinear, due to  to be linearly, not antilinearly, isomorphic with
to be linearly, not antilinearly, isomorphic with  , we take the partial application
, we take the partial application  . This mapping from
. This mapping from  (note the non-standard notation!). As such,
(note the non-standard notation!). As such,  ; the dual space is isomorphic to the complex conjugate space.
; the dual space is isomorphic to the complex conjugate space. . Because
. Because  , we can see the operator as a linear map
, we can see the operator as a linear map  , or expanded out,
, or expanded out,  . Tensoring up, this is equivalently a linear map
. Tensoring up, this is equivalently a linear map  ; we can see the operator as a quadratic form in a bra and a ket.
; we can see the operator as a quadratic form in a bra and a ket. . We would like to understand real structure on linear operators through real structure on tensored maps of this type. If
. We would like to understand real structure on linear operators through real structure on tensored maps of this type. If  is linear, we define the real structure
is linear, we define the real structure  . As a quick check:
. As a quick check: .
. :
: .
. satisfies
satisfies  ; note
; note  . As such,
. As such,
 . This justifies the Hermitian adjoint as the canonical real structure on the linear operator space
. This justifies the Hermitian adjoint as the canonical real structure on the linear operator space  , as is standard in operator algebra.
, as is standard in operator algebra.

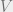 is a Hilbert space, this holds for all
is a Hilbert space, this holds for all  iff
iff  , i.e. A is Hermitian. This is significant, because Hermitians are often used to represent observables (such as in
, i.e. A is Hermitian. This is significant, because Hermitians are often used to represent observables (such as in  with a real structure σ be called self-adjoint iff
with a real structure σ be called self-adjoint iff  . As an important implication of the above, if
. As an important implication of the above, if  is Hermitian, then
is Hermitian, then  , unitary operators are those for which
, unitary operators are those for which  . We will consider time evolution as a family of unitary operators
. We will consider time evolution as a family of unitary operators  for real t, which is group homomorphic as a family (
for real t, which is group homomorphic as a family ( ).
). (for real a). The unitary evolution is given by
(for real a). The unitary evolution is given by  , a multiplicative factor on the phasor to advance it in time. By convention, we have decided that time evolves in the +i direction (multiplicatively), assuming
, a multiplicative factor on the phasor to advance it in time. By convention, we have decided that time evolves in the +i direction (multiplicatively), assuming  . We can find this direction explicitly by differentiating:
. We can find this direction explicitly by differentiating:  .
.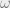 . Interpreting quantum phasors is less straightforward. We can still take the derivative
. Interpreting quantum phasors is less straightforward. We can still take the derivative  , which approximates
, which approximates  as
as  . We recover
. We recover  , which generalizes
, which generalizes  in the single-phasor case.
in the single-phasor case. for Hermitian H; note
for Hermitian H; note  is Hermitian iff H is. In the specific case of the Schrödinger equation,
is Hermitian iff H is. In the specific case of the Schrödinger equation,  where
where  is the
is the  is the reduced Planck constant (a positive real number). The direction of the action of i in quantum state space is meaningful through the Schrödinger convention
is the reduced Planck constant (a positive real number). The direction of the action of i in quantum state space is meaningful through the Schrödinger convention  (as opposed to
(as opposed to  ).
). , while
, while  . In the real structure on linear operator space
. In the real structure on linear operator space  , a Hermitian is self-adjoint, like a real number in
, a Hermitian is self-adjoint, like a real number in  is skew-adjoint (
is skew-adjoint ( ), like an imaginary number in
), like an imaginary number in  for real b).
for real b). (satisfying
(satisfying  ) is anti-linear, due to the relationship between time and phase. In the simpler case,
) is anti-linear, due to the relationship between time and phase. In the simpler case,  , though in systems with half-integer spin,
, though in systems with half-integer spin,  ; see
; see  , the
, the  ; group composition “applies the right element first”. Each channel permutation can be categorized as either being the identity, swapping two channels, or rotating channels in either the red-to-green or green-to-red directions; there are 6 elements of
; group composition “applies the right element first”. Each channel permutation can be categorized as either being the identity, swapping two channels, or rotating channels in either the red-to-green or green-to-red directions; there are 6 elements of ![[S_3, Set]](https://s0.wp.com/latex.php?latex=%5BS_3%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , where
, where  where
where  is group homomorphic in its first argument:
is group homomorphic in its first argument:  and
and  . Since
. Since  is generally clear from context, we also write
is generally clear from context, we also write  as
as  . (Note, p is a
. (Note, p is a  performs a red/green swap on its image argument, like a shader.
performs a red/green swap on its image argument, like a shader. between color qualia spaces
between color qualia spaces  has, for any
has, for any  , the equality
, the equality ![CQS \cong [S_3, Set]](https://s0.wp.com/latex.php?latex=CQS+%5Ccong+%5BS_3%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . Let’s quickly list some examples of equivariant maps:
. Let’s quickly list some examples of equivariant maps: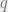 to
to  for a non-trivial
for a non-trivial 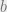 , i.e. swapping two channels, or rotating channels.
, i.e. swapping two channels, or rotating channels. is a function on images. Now to check equivariance, we ask if
is a function on images. Now to check equivariance, we ask if  . But this is only true when
. But this is only true when  , the group identity. Note
, the group identity. Note  is the set of elements reachable through group actions,
is the set of elements reachable through group actions,  . Now let the orbit map
. Now let the orbit map  map elements to their orbits, effectively quotienting over channel permutations. The orbit map relates to equivariance in the following way: for any equivariant
map elements to their orbits, effectively quotienting over channel permutations. The orbit map relates to equivariance in the following way: for any equivariant  commuting,
commuting,  .
.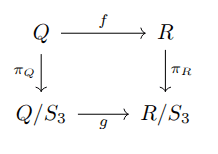
 must map elements of a single Q-orbit to a single R-orbit, which allows defining
must map elements of a single Q-orbit to a single R-orbit, which allows defining 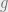 commuting. Any alternative choice would fail commutation on some Q-orbit.)
commuting. Any alternative choice would fail commutation on some Q-orbit.) has elements
has elements  ; it is trivial.
; it is trivial. has elements
has elements  representing chirality. Channel reflections (RBG, GRB, BGR) flip chirality, rotations preserve it. (Imagine three balls corresponding to primary colors, with sticks connecting them in a triangle; chirality-reversing operations require flipping the triangle over vertically.)
representing chirality. Channel reflections (RBG, GRB, BGR) flip chirality, rotations preserve it. (Imagine three balls corresponding to primary colors, with sticks connecting them in a triangle; chirality-reversing operations require flipping the triangle over vertically.) has elements {R, B, G} representing primary colors. Group operations work straightforwardly, e.g.
has elements {R, B, G} representing primary colors. Group operations work straightforwardly, e.g.  .
. has as elements total orderings of primary colors (e.g. R > B > G), of which there are 6. Group operations work straightforwardly, e.g.
has as elements total orderings of primary colors (e.g. R > B > G), of which there are 6. Group operations work straightforwardly, e.g.  .
. to only 9 realizable signatures. 4 of these signatures are clearly trivial, as they map to
to only 9 realizable signatures. 4 of these signatures are clearly trivial, as they map to  : identity and chirality-reversal.
: identity and chirality-reversal. , the identity.
, the identity. , which assign distinct chiralities to the two cyclic orbits, {(R > G > B), (B > R > G), (G > B > R)} and {(B > G > R), (R > B > G), (G > R > B)}.
, which assign distinct chiralities to the two cyclic orbits, {(R > G > B), (B > R > G), (G > B > R)} and {(B > G > R), (R > B > G), (G > R > B)}. , which pick out either the greatest, middle, or least primary color.
, which pick out either the greatest, middle, or least primary color. corresponding to each of the
corresponding to each of the  are as follows:
are as follows: , determine how
, determine how  , which has a finite combinatorial characterization.
, which has a finite combinatorial characterization.
 is the set of equivariant maps between color qualia spaces S and T, and
is the set of equivariant maps between color qualia spaces S and T, and  are set-theoretic dependent product and sum.
are set-theoretic dependent product and sum.![[O(2), Set]](https://s0.wp.com/latex.php?latex=%5BO%282%29%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) .)
.) . A vector space has addition, zero, and scalar multiplication defined, which have the standard commutativity/associativity/distributivity properties. The category
. A vector space has addition, zero, and scalar multiplication defined, which have the standard commutativity/associativity/distributivity properties. The category  has as objects vector spaces (over the field
has as objects vector spaces (over the field  and
and  . (Advanced readers may see
. (Advanced readers may see  , which has as elements pairs (u, v) with
, which has as elements pairs (u, v) with  , and for which addition and scalar multiplication are element-wise, is also a vector space. The direct sum is both a product and a coproduct.
, and for which addition and scalar multiplication are element-wise, is also a vector space. The direct sum is both a product and a coproduct. and
and  be the projections of the direct sum onto its elements. Let us suppose a third vector space T and linear maps
be the projections of the direct sum onto its elements. Let us suppose a third vector space T and linear maps  and
and  . Let
. Let  be defined as
be defined as  . Now
. Now  uniquely commutes:
uniquely commutes:
 be defined as
be defined as  , and similarly let
, and similarly let  be defined as
be defined as  . Let us suppose a third vector space W and linear maps
. Let us suppose a third vector space W and linear maps  and
and  . Let
. Let ![[f, g] : U \oplus V \rightarrow W](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D+%3A+U+%5Coplus+V+%5Crightarrow+W&bg=eeeeee&fg=666666&s=0&c=20201002) be defined as
be defined as  = f(u) + g(v)](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D%28u%2C+v%29+%3D+f%28u%29+%2B+g%28v%29&bg=eeeeee&fg=666666&s=0&c=20201002) . Now
. Now ![[f, g]](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D&bg=eeeeee&fg=666666&s=0&c=20201002) uniquely commutes:
uniquely commutes:
 be a zero function; since the direct sum also satisfies the identities
be a zero function; since the direct sum also satisfies the identities  , by definition it is a
, by definition it is a 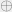 .
. (in C), we may uniquely decompose it as
(in C), we may uniquely decompose it as  for some
for some  . And similarly, we may uniquely decompose
. And similarly, we may uniquely decompose  as
as ![h = [f, g]](https://s0.wp.com/latex.php?latex=h+%3D+%5Bf%2C+g%5D&bg=eeeeee&fg=666666&s=0&c=20201002) for some
for some  .
. is an object for natural
is an object for natural  . Now the n-ary biproduct is
. Now the n-ary biproduct is  . We take the empty biproduct to be 0. We can also generalize the projections
. We take the empty biproduct to be 0. We can also generalize the projections  , the injections
, the injections  , the “row-wise” combination
, the “row-wise” combination  be objects in C, for natural
be objects in C, for natural  and
and  . Suppose
. Suppose  . We first decompose h “row-wise”, as
. We first decompose h “row-wise”, as  where
where  . Then we decompose each row “column-wise”, as
. Then we decompose each row “column-wise”, as ![h_j = [h_{j,1}, \ldots, h_{j,m}]](https://s0.wp.com/latex.php?latex=h_j+%3D+%5Bh_%7Bj%2C1%7D%2C+%5Cldots%2C+h_%7Bj%2Cm%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) where
where  . We can now write h in matrix style, as
. We can now write h in matrix style, as ![h = \langle [ h_{1, 1}, \ldots, h_{1, m} ], \ldots, [h_{n, 1}, \ldots, h_{n, m}] \rangle](https://s0.wp.com/latex.php?latex=h+%3D+%5Clangle+%5B+h_%7B1%2C+1%7D%2C+%5Cldots%2C+h_%7B1%2C+m%7D+%5D%2C+%5Cldots%2C+%5Bh_%7Bn%2C+1%7D%2C+%5Cldots%2C+h_%7Bn%2C+m%7D%5D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) ; the notation
; the notation  can be visualized as vertical matrix concatenation, and
can be visualized as vertical matrix concatenation, and ![[ \ldots ]](https://s0.wp.com/latex.php?latex=%5B+%5Cldots+%5D&bg=eeeeee&fg=666666&s=0&c=20201002) can be visualized as horizontal matrix concatenation.
can be visualized as horizontal matrix concatenation.
 . Now a map
. Now a map  decomposes as a
decomposes as a  matrix of linear maps
matrix of linear maps  . This is not quite a traditional matrix, but note that linear maps of type
. This is not quite a traditional matrix, but note that linear maps of type  are always multiplication by a constant real slope. Representing each
are always multiplication by a constant real slope. Representing each  by its slope yields a more traditional numeric matrix.
by its slope yields a more traditional numeric matrix. for some natural n. Specifically, if a space U has a basis
for some natural n. Specifically, if a space U has a basis  , then the linear map
, then the linear map  defined as
defined as  is an isomorphism. Hence, matrix representation extends to maps between finite-dimensional vector spaces.
is an isomorphism. Hence, matrix representation extends to maps between finite-dimensional vector spaces. be natural, and let
be natural, and let  be objects in C (for naturals
be objects in C (for naturals  ). Suppose we have maps
). Suppose we have maps  and
and  . We can write f in matrix form (
. We can write f in matrix form ( ), and similarly g (
), and similarly g ( ).
).
 . We fix i, k and consider the entry
. We fix i, k and consider the entry  . Now note
. Now note ![\pi_k \circ g = [g_{k, 1}, \ldots, g_{k, n}]](https://s0.wp.com/latex.php?latex=%5Cpi_k+%5Ccirc+g+%3D+%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) and
and  . Therefore
. Therefore![h_{k, i} = [g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle](https://s0.wp.com/latex.php?latex=h_%7Bk%2C+i%7D+%3D+%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002)

 in
in  can also be written:
can also be written:
![[g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle = \sum_{j=1}^n (g_{k, j} \circ f_{j, i})](https://s0.wp.com/latex.php?latex=%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle+%3D+%5Csum_%7Bj%3D1%7D%5En+%28g_%7Bk%2C+j%7D+%5Ccirc+f_%7Bj%2C+i%7D%29&bg=eeeeee&fg=666666&s=0&c=20201002) to semiadditive categories in general; for details, see
to semiadditive categories in general; for details, see ![\langle [h_{1, 1}, \ldots, h_{1, m}], \ldots, [h_{n, 1}, \ldots, h_{n, m}] \rangle](https://s0.wp.com/latex.php?latex=%5Clangle+%5Bh_%7B1%2C+1%7D%2C+%5Cldots%2C+h_%7B1%2C+m%7D%5D%2C+%5Cldots%2C+%5Bh_%7Bn%2C+1%7D%2C+%5Cldots%2C+h_%7Bn%2C+m%7D%5D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) with
with  .
.![[g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle](https://s0.wp.com/latex.php?latex=%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) .
. , or is at least isomorphic. Solomonoff induction, and similarly the speed prior, posit that reality consists of an input to a universal Turing machine (specifying some other Turing machine and its input), and its execution trajectory, producing digital subjective experience.
, or is at least isomorphic. Solomonoff induction, and similarly the speed prior, posit that reality consists of an input to a universal Turing machine (specifying some other Turing machine and its input), and its execution trajectory, producing digital subjective experience. specify the universe’s physical state as a function of the reality state. Let
specify the universe’s physical state as a function of the reality state. Let  specify the universe’s mental state as a function of the reality state. These presumably exist under the above assumptions, because physics and mind are both aspects of reality, though these need not be efficiently computable functions. (The general structure of physics and mind being aspects of reality is inspired by neutral monism, though it does not necessitate neutral monism.)
specify the universe’s mental state as a function of the reality state. These presumably exist under the above assumptions, because physics and mind are both aspects of reality, though these need not be efficiently computable functions. (The general structure of physics and mind being aspects of reality is inspired by neutral monism, though it does not necessitate neutral monism.)
 means “there exists a unique”.
means “there exists a unique”.
 commuting (
commuting ( ), though again, h need not be efficiently computable.
), though again, h need not be efficiently computable. , specifically, that we do not exist in a digital computer simulation. While I don’t accept the simulation hypothesis as likely, it seems presumptuous to reject it on philosophy of mind grounds.
, specifically, that we do not exist in a digital computer simulation. While I don’t accept the simulation hypothesis as likely, it seems presumptuous to reject it on philosophy of mind grounds. as the mainline model. (Note that Chalmers believes natural supervenience holds but that strict physicalism is false.)
as the mainline model. (Note that Chalmers believes natural supervenience holds but that strict physicalism is false.) being the initial state. A value function on states satisfies:
being the initial state. A value function on states satisfies:
