Type B physicalism is a view in philosophy of mind, and “powerful qualities” (PQ) theory is a view in the metaphysics of properties. They share an important similarity: they both combine conceptual dualism with ontic monism. Type B physicalists hold that phenomenal concepts (e.g. concepts of reddish experience) are not analytically definable in terms of physical concepts, yet can co-refer (“pain is C-fiber firing” being a simplified example), and that every property is a physical property. PQ theorists claim that there are both qualitative concepts (referring to qualities such as the redness of a red object) and dispositional concepts (referring to tendencies such as the disposition to reflect ~700nm light), and that every property is both really qualitative and really dispositional; hence, qualitative concepts co-refer with dispositional concepts.
I suggest that type B physicalism combines well with powerful qualities theory. First, generalizing phenomenal concepts to qualitative concepts makes phenomenal concept theory less ad hoc. Second, considering “phenomenally conscious” as a secondary qualitative concept, and considering un-conscious qualities to exist, yields a more comprehensible theory. Third, philosophical debates about the two views are similar, and type B physicalists find themselves in a similar dialectical place to PQ theorists.
Background
I take type B physicalism to be the conjunction of three theses:
- Physicalism: There are no non-physical mental properties. Here, a property is physical if it is specified by a physical predicate, and a physical predicate is a predicate definable in terms of the predicates of fundamental physics, or in other words, a predicate logically supervenient on those of fundamental physics. Such predicates include Fodor’s “wildly disjunctive” functional predicates and ordinary scientific predicates. I take it that two predicates can refer to the same property, the way two nouns can refer to the same thing (“Hespherus is Phosphorous”).
- Non-analyzability: There are concepts of phenomenal experience (“phenomenal concepts”) which have no analytic definitions in terms of physical predicates. In other words, phenomenal concepts form predicates that are not logically supervenient on physical predicates. In particular, it is ideally negatively conceivable that there could be beings physically the same as humans but with different phenomenal properties, e.g. P-zombies, or people whose color qualia are spectrum-inverted.
- Phenomenal realism: Some phenomenal concepts are positively satisfied. In particular, some humans are phenomenally conscious.
Non-analyzability rules out analytic functionalism; phenomenal realism rules out strong illusionism. I take property dualism and Russellian monism to be paradigm non-physicalist views.
Powerful qualities theory, in strong form, is John Heil’s identity view:
If
is an intrinsic property of a concrete object,
, is
, and each of these is
.
As an example, perhaps an object’s qualitative redness is a light reflectance property, and perhaps an object’s sphericity is its spherical dispositions (e.g. rolling down slopes). Dispositional properties are more straightforwardly measurable by physical devices, e.g. an object’s disposition to exert forces or reflect light can be measured by standard instruments. The physics notion of “observable” includes dispositional properties that are only measurable in ideal imagination, not in practice.
Quoting Philip Goff on sensory qualities (Consciousness and Fundamental Reality):
Before Galileo, philosophers took the world to be full of sensory qualities: colors, smells, tastes, sounds. And intuitively one cannot capture the redness of a tomato, the spicy taste of paprika, or the sweet smell of flowers in the austere, abstract language of mathematics. Galileo got around this problem by stripping the world of such qualities and locating them in the soul.
And quoting SEP on primary and secondary qualities:
Many philosophers maintain there is a significant difference between primary and secondary qualities but disagree about its foundation. It may be plausible that we perceive things as having a small number of basic qualities which are determinates or degrees of the following: size, figure, extension, duration, motion, position, color, taste, odor, sound, heat, coldness, and tactual qualities such as hardness, softness, roughness and smoothness. The first six (to which solidity and number are sometimes added) are called “primary”; roughly speaking, they are said to be real objective properties of objects and to be distinctly known. The remaining, called “secondary”, are said to be in some way—metaphysically, epistemically, linguistically—derivative, less than fully real, or otherwise metaphysically feeble; or misleading, subjective, ambiguous, or otherwise not perspicuous.
Physics has more to say on primary qualities than secondary qualities. Qualia are generally considered to have secondary qualities even if objects don’t have them, e.g. the redness of an experience of red light. For the purposes of this post, I will consider secondary qualities to be ones without accepted conceptual reductions to physics. In this sense, I don’t consider “heat” a secondary quality, except as qualia.
Since PQ theorists hold that every dispositional property is a qualitative property, they believe that secondary qualities exist both in objects and in the mind. PQ is contrasted with a “pure powers” view, under which only dispositional and not qualitative properties are positively instantiated, and a “pure qualities” view, under which only qualitative and not dispositional properties are positively instantiated. Roughly, the objection to “pure powers” is that dispositional properties face a regress problem, never grounding in any disposition for a variable to take on a value; and the objection to “pure qualities” is that non-dispositional properties are physically and epistemically idle.
A natural “conceptual dualist” approach PQ theorists can take, analogous to that of type B physicalists, is to say that concepts and predicates can be dispositional-only or quality-only, but that properties are all simultaneously dispositional and qualitative. This approach helps explain why people can believe that PQ is false without running into analytic contradiction. It is not supposed to be obvious that dispositional properties are all qualitative properties and vice versa; it could perhaps be the case that no knowledge of dispositional predicates suffices to know which qualitative predicates are satisfied. This non-analyzability could include the philosophy of mind non-analyzability of “red qualia” into physical or functional concepts.
The concordance between type B physicalism and powerful qualities has been noted in the literature (H. Taylor 2017, H. Taylor 2024).
Is the red in the head?
We more easily bridge the gap between type B physicalism and powerful qualities by imagining a world w’ of direct realists, following Byrne 2006. In this world, people believe that the secondary quality of color is a property of objects. They don’t believe in qualia; they believe there are really colors on the objects out there, and that they directly perceive these colors. Moreover, they do not believe object colors are analytically reducible to physical properties. Their debates mirror the qualia debates of our own (predominately indirect-realist) world.
These w’ inhabitants consider a physical property 

As such, inhabitants of w’ face a hard problem of color. There are at least 3 general approaches:
- Dualism: Color properties are non-physical properties. Redness is not
- Eliminativism: No color predicates are positively satisfied. Color qualities do not exist.
- Identity: Redness is
The arguments against dualism need not be rehearsed. Inhabitants of w’ are strongly disposed to reject color eliminativism. And they usually reject a priori conceptual links on the basis of conceivability arguments and related intuitions. As such, a posteriori identity theory is well worth considering, though it faces conceptual obstacles.
The identity theory equates a qualitative property (redness) with a dispositional property (
If this identity (“redness is
Phenomenal concepts as qualitative concepts
An important element of type B physicalism is the phenomenal concept strategy (PCS). The objective is to explain the conceivability gap between physical and phenomenal predicates (e.g. why P-zombies are conceivable), in a way compatible with physicalism and phenomenal realism. In particular, PCS should explain why there are no analytic definitions of phenomenal concepts in terms of physical and functional ones.
The general idea is that, when people have experiences, they form phenomenal concepts of those experiences. When Mary of Mary’s Room sees red the first time (say, by seeing a tomato), she forms a direct phenomenal concept (call it R) on this basis. This allows her to form a justified true belief she lacked before: “Tomatoes look like <R> to me”, in her “mentalese” private language. Here, “<R>” indicates a use, not a mention, of the phenomenal concept R.
To preserve compatibility with physicalism, this new knowledge must be about a physical property. In particular, there is some predicate P, which can in principle be stated in physical language, which is true of Mary if and only if “Tomatoes look like <R> to me” is true of her (in her mental language), picking out the same (physical) property. Mary could in principle have known P without leaving her room, even though it refers to the same property that “Tomatoes look like <R> to me” does. Again, this is conceptual dualism combined with ontic monism.
One criticism of PCS is that it is ad hoc. Phenomenal concepts are described as “special”, and in particular “direct demonstrative” and/or “quotational” (Foerster 2019). These features are posited to explain non-analyzability while preserving reference to phenomenal features, which could plausibly be physical features in the real world, but could conceivably come apart (such as in the P-zombie hypothetical). Moreover, some PCS theorists hold that phenomenal concepts cannot entirely be explained in physical terms, since phenomenal concepts must be used, not just mentioned, in a full explanation of themselves (Balog 2012).
Powerful qualities can fit into PCS in that the explanatory gap between physical and phenomenal concepts contains an explanatory gap between dispositional and qualitative concepts. Physics in general deals with dispositional concepts and primary qualitative concepts (e.g. position). Inhabitants of w’ find that they cannot explain the secondary quality of color in physical terms. This dispositional-to-qualitative inference does not get easier when we consider color quality to be in the mind (as “qualia”). It isn’t any easier to explain why the brain has red qualia than to explain why objects emitting ~700nm light have red color quality.
Quoting Henry Taylor (2017) on the matter:
Recall that the adherent of the PCS has to explain how scientific and phenomenal concepts could both correctly and substantively characterise the same experience, without claiming that they do so by describing different properties or parts of the experience. If the advocate of the PCS adopts the powerful qualities view, she can solve this problem. On such a view, an experience has properties, which are powerful qualities. A scientific concept has a mode of presentation that characterises an experience’s properties in a particular way (a dispositional way), whilst a phenomenal concept has a mode of presentation that characterises the very same properties of the experience in another way (a purely qualitative way). Importantly, on this view both phenomenal and scientific concepts substantively and correctly characterise the experiences they refer to.
Phenomenal concepts theories are less ad hoc if they can show that phenomenal concepts are not sui generis. Since concepts of secondary qualities are generally considered to be non-physical concepts (at least, not clearly physical concepts), phenomenal concepts can be considered as a special case of qualitative concepts. Once this step is taken, the powerful qualities view helps make sense of how phenomenal concepts can co-refer with physical concepts, as “redness” plausibly co-refers with
Unconscious qualities
Unlike in w’, philosophers in our world are disposed to locate red quality in the mind, not in red objects. This “re-location” strategy can be pragmatic, in allowing science to proceed without explaining secondary qualities. However, re-location raises the problem of explaining qualia (as mental versions of qualities) down the line.
Re-location is especially problematic for the concept “phenomenal consciousness”. Most philosophers of mind believe there is a fact of the matter about whether any particular bat is phenomenally conscious. If a bat is phenomenally conscious, then the consciousness of the bat is supposed to be an intrinsic feature of that bat. If such bat consciousness cannot be analytically reduced to physical or functional predicates (as Nagel claimed in his original essay), then the “re-location” strategy for secondary qualities suggests re-locating “the bat’s phenomenal consciousness” into the minds of humans. But this raises regress issues, and presses towards illusionism; compare with Hofstader’s “the self is an hallucination hallucinated by an hallucination”.
When discussing “phenomenal consciousness”, philosophers of our predominately indirect-realist world sound like the direct-realist w’ philosophers discussing “redness”. A natural PQ view, here, is that “phenomenal consciousness” is a qualitative concept, and co-refers with some dispositional (and likely physical) concept, perhaps a variant of Ned Block’s “access consciousness” (Block 1995). Again, considering “phenomenal consciousness” to be a secondary qualitative concept is less ad hoc than considering it to be a special kind of non-physical concept.
If “phenomenal consciousness” is a qualitative concept, a natural next question is whether “<R> qualia” is a qualitative concept; here, suppose R is your phenomenal concept associated with🔴. Supposing that color qualia inverts are ideally conceivable, “<R> qualia” cannot be a physical concept. The natural inference is that “<R> qualia” is a qualitative concept, and so are phenomenal concepts more generally.
Consider the simplified psycho-physical identity, “pain is C-fiber firing”. “Pain” is, presumably, a secondary qualitative concept. “C-fiber firing” could be interpreted as dispositional (in terms of being physically measurable), or perhaps also including primary qualities such as shape. Plausibly, C-fiber firing can occur with or without phenomenal consciousness. In general, neural clusters can spike with no associated access consciousness. Similar considerations apply to “functional pain”, i.e. “when people suffer bodily damage, psychological distress, etc., they often enter states that tend to generate avoidant or fighting behavior” (Kammerer 2022); in principle, functional pain could occur unconsciously.
The rough suggestion here is that it is possible to have “unconscious pain”, “unconscious <R> perception”, and so on. The visual cortex can have firing patterns as if seeing red, but with no access consciousness or phenomenal consciousness. Imagine a Venn diagram of “<R> perception” and “phenomenally conscious”, with “<R> qualia” being at the intersection. If “<R> qualia” and “phenomenally conscious” are both qualitative concepts, this strongly suggests that “<R> perception” is, likewise, a qualitative concept.
Type B physicalists, in accepting identity theory, will therefore gain theoretical virtue in also positing unconscious secondary qualities. The general form is that there are brain states that, if one were conscious of them, would have qualia; what separates these states from qualia is absence of phenomenal consciousness.
Of course, this raises the question of where to draw the line. PQ theory in its strong form says “nowhere”: all properties are qualitative in addition to being dispositional. The natural way to restrict only some physical properties to be qualitative is through restricting secondary qualities to only apply to qualia. However, both the idea of “phenomenally conscious” as a qualitative concept, and unconscious qualities in type B identity theory, suggest this is not the right place to draw the line.
Moreover, in principle, if animals can sense dispositional properties (e.g. light reflectance) qualitatively, then so can a large range of other beings, including aliens, cyborgs, and AIs; these “xenoqualia” hypotheticals suggest that a large range of dispositional properties could, in principle, have corresponding secondary qualities.
These considerations suggest that PQ theory is a reasonable default in the absence of a principled line between physical properties which are qualitative, and physical properties which are not qualitative. We can see perception as signal transduction, e.g. from light to optic nerve firing patterns to visual cortex firing patterns and so on; if later stages have secondary qualities (due to having qualia), why not earlier stages?
Contrasting with other views
A unifying thread between type B physicalism and PQ theory is “conceptual dualism, ontic monism”. Quoting John Taylor (2012) on PQ:
The second point I would like to emphasise is that, in stating the powerful qualities view, there is a temptation to think of the qualitative/categorical and the dispositional as ‘parts’ or ‘aspects’ of the single underlying property, but this is a mistake. When we think of a property under a qualitative/categorical concept, we are not thinking of a part or an aspect of the property, but we are thinking of the whole property in a certain way. Equally, to think of the property under a dispositional concept is not to think of only an ‘aspect’ of the property but again is to consider the whole property in a certain different way.
Compare with Janet Levin (2018) on type B physicalism:
These [phenomenal] concepts, Type B physicalists maintain, have special features that explain how they can denote physical-functional properties of the brain even though they are not connected a priori to any physical-functional concepts—and therefore an epistemic gap between the phenomenal and the physical provides no evidence that they are (metaphysically) distinct. Moreover, Type B physicalists suggest, it is this lack of connection between these concepts that explains why phenomenal-physical identity statements may seem uniquely mysterious or unintelligible (and also why it’s rational to question phenomenal-physical identity statements, no matter how much we know about the world). In short—as many put it—Type B physicalists embrace conceptual dualism while explaining why this does not entail metaphysical dualism.
These two passages are saying almost the same thing. “Physical” does not mean exactly the same thing as “dispositional”, but is close. “Functional” can mean “dispositional”; function is often thought of in terms of input/output processes. Phenomenal concepts generally present their referents (e.g. “this reddish experience right now”) as having qualities, not in terms of their dispositions (e.g. disposition to psychologically react as if to red light).
Let us contrast both these views with Russellian monism. According to Russellian monism, physics gives only structural and relational properties, leaving open the intrinsic nature of its elements, “quiddities”, which are in some way relevant to consciousness. Russellian panqualityism, in particular, claims that quiddities are qualities.
Russellian monism disagrees with type B physicalism, in that according to Russellian monism, quiddity properties are real and relevant to the mind, and are not physical properties, since physical properties are all structural and relational. Russellian panqualityism disagrees with the powerful qualities view, in that it considers qualities fundamental, not equating them with any dispositional properties. Other forms of Russellian monism, such as Russellian panpsychism, are in a similar boat, in that they consider qualia and/or consciousness fundamental and qualitative, and do not equate them with dispositions.
Let us consider a case of reddish experience, or “red qualia”, when seeing a tomato. Russellian monists such as Philip Goff will tend to think that such experiences reveal the essence of the property (phenomenal redness), and that this phenomenality (or a proto-phenomenal precursor) is fundamental to the universe, unequal to any structural or relational property. Type B physicalists will tend to think that such experiences reveal some neural and/or functional property (call it NeuralR, some red-correlated neural firing pattern in the visual cortex) under a phenomenal mode of presentation, which does not reveal the neural basis. The disagreement is about how fundamental a property is being revealed. “Powerful qualities” adds that the property revealed by having reddish experiences can be genuinely secondarily-qualitative, while still physical.
Russellian monism does, however, align with the powerful qualities view, in saying that “relations without relata” would face regress. There is, conversely, alignment between a “pure powers” metaphysical view, ontic structural realism (“structure is all there is”), and illusionism in philosophy of mind: the basic idea is to eliminate secondary qualities (and perhaps qualities in general), and not equate them with anything physical. (See Keith Frankish’s “Galileo’s Real Error” for an illusionist perspective on qualities.)
Property dualism, in positing an ontic difference between physical and phenomenal properties, mirrors alternatives to PQ which consider qualitative properties to be distinct from dispositional properties. The basic intuition, in both cases, is that two kinds of property exist, and that they cannot be identical.
Analytic functionalists tend to think that everything in experience has analytic definitions in terms of physics, and in particular, in terms of the dispositional/functional implications of physics. This applies to phenomenal consciousness and concepts of qualia more generally. Analytic functionalism, if successful, challenges the “conceptual dualism” of both type B physicalism and the powerful qualities view: the two concepts may be analytically equivalent in a non-obvious way. At the same time, analytic functionalism affirms psycho-physical identity and quality-disposition identity, in common with type B physicalism and PQ.
Conclusion
Type B physicalism is notable in combining conceptual dualism with ontic monism. This is a significant philosophical commitment, contra the conceivability-possibilty link and Chalmers’ modal rationalism. The powerful qualities view, likewise, holds that qualitative and dispositional concepts are distinct, but can refer to the same property anyway. These views go well together, in taking on similar commitments and having overlapping implications.
In particular, PQ shows how the phenomenal / physical conceptual divide contains the quality / disposition conceptual divide, so that phenomenal concepts belong in a larger category of qualitative concepts, rather than being sui generis. There are good reasons for type B physicalists to consider “phenomenal consciousness” to be a qualitative concept, and to believe in unconscious qualities; such broadening of the meta-concept “qualitative concept” tends towards PQ unless a line can be drawn, and “phenomenal consciousness” is an unlikely boundary.
The powerful qualities view implies that the universe is full of qualities, few of which are ever experienced. There are more colors than the eye can see, more sounds than the ear can hear. This sounds like panqualityism, but disagrees rather specifically with Russellian panqualityism on whether qualities equal dispositions.
I have focused in this essay on explaining type B physicalism, and arguing for PQ conditionally, rather than on evaluating the different views in philosophy of mind. To my mind, the most important views are the five: analytic functionalism, type B physicalism, strong illusionism, property dualism, and Russellian monism. Comparing these views is hard in part because understanding what it would mean for any of these views to be true is difficult. Nagel wrote in 1974, “physicalism is a position we cannot understand because we do not at present have any conception of how it might be true”. Hopefully, relating type B physicalism to powerful qualities helps to develop a positive conception of what it would mean for physicalism to be true, one that can be reasonably understood by humans using the concepts we tend to use.
 .
.
 . Its state is best thought of as also including its velocity
. Its state is best thought of as also including its velocity  . Note that
. Note that  has constant magnitude, corresponding to conservation of energy. Now over time, the normalized
has constant magnitude, corresponding to conservation of energy. Now over time, the normalized  point moves in a circle. Phase-translating the system would imply cyclical movement through phase space; a full cycle happens in time
point moves in a circle. Phase-translating the system would imply cyclical movement through phase space; a full cycle happens in time  . A complex scalar specifies both how to phase-translate a phasor, and how to scale it (here, scaling would apply to both position and velocity). By representing the phasor
. A complex scalar specifies both how to phase-translate a phasor, and how to scale it (here, scaling would apply to both position and velocity). By representing the phasor  , multiplying by a complex scalar will phase-translate and scale. Here, multiplying by i represents moving forward a quarter of one cycle, though in other representations, –i would do so instead. The phasor is inherently more symmetric than the scalar; which phase to consider “1” in this complex representation, and whether multiplication by i steps time forwards or backwards, are fairly arbitrary.
, multiplying by a complex scalar will phase-translate and scale. Here, multiplying by i represents moving forward a quarter of one cycle, though in other representations, –i would do so instead. The phasor is inherently more symmetric than the scalar; which phase to consider “1” in this complex representation, and whether multiplication by i steps time forwards or backwards, are fairly arbitrary.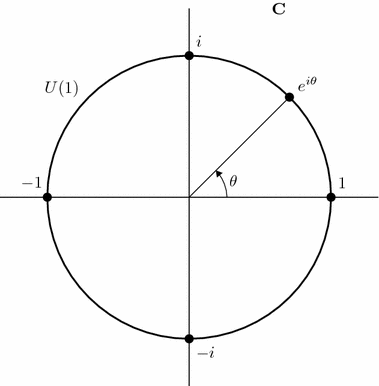
 the non-zero complex numbers, considered as a group under multiplication. An element of the group can be thought of as a combined positive scaling and phase translation. Let
the non-zero complex numbers, considered as a group under multiplication. An element of the group can be thought of as a combined positive scaling and phase translation. Let 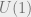 be the sub-group of
be the sub-group of  be the positive reals considered as a group under multiplication. Now the decomposition
be the positive reals considered as a group under multiplication. Now the decomposition  holds: multiplication by a non-zero complex number combines scaling and phase translation.
holds: multiplication by a non-zero complex number combines scaling and phase translation.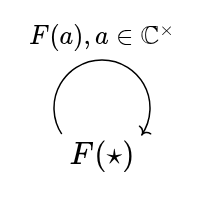
 ), and one morphism per element of G. A convenient notation for the category of
), and one morphism per element of G. A convenient notation for the category of  .
. (
( ) satisfying
) satisfying  and
and  . We now have a set of elements that can be scaled and phase-translated. Hence, S conceptually represents a set of phasors (or multi-phasors), which are acted on by complex scalars.
. We now have a set of elements that can be scaled and phase-translated. Hence, S conceptually represents a set of phasors (or multi-phasors), which are acted on by complex scalars.
 is equivariant iff
is equivariant iff  for all
for all  . This is looking a lot like linearity, though we do not have zero or addition. To handle additivity, it will help to factor out the
. This is looking a lot like linearity, though we do not have zero or addition. To handle additivity, it will help to factor out the  semimodules (to model negation as action by
semimodules (to model negation as action by  ), real vector spaces are mathematically nicer. Let
), real vector spaces are mathematically nicer. Let  be the category of real vector spaces and linear maps between them.
be the category of real vector spaces and linear maps between them.![[BU(1), \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BBU%281%29%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . Each element is a real vector space with a U(1) action. We can write the action as
. Each element is a real vector space with a U(1) action. We can write the action as  for complex unitary a. Note
for complex unitary a. Note  is linear for fixed a.
is linear for fixed a. is U(1)-equivariant iff
is U(1)-equivariant iff  for all complex unitary a.
for all complex unitary a. for
for  , which is valid for ideal harmonic oscillators, and of course relevant to destructive interference. We now extend S to a complex vector space, defining scalar multiplication as
, which is valid for ideal harmonic oscillators, and of course relevant to destructive interference. We now extend S to a complex vector space, defining scalar multiplication as  for real a, b. This is a standard
for real a, b. This is a standard  . The assumption of opposite-phase cancellation is therefore the only distinction between a U(1)-symmetric real vector space in
. The assumption of opposite-phase cancellation is therefore the only distinction between a U(1)-symmetric real vector space in ![[BU, \mathsf{Vect}_\mathbb{R}]](https://s0.wp.com/latex.php?latex=%5BBU%2C+%5Cmathsf%7BVect%7D_%5Cmathbb%7BR%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) and a proper complex vector space.
and a proper complex vector space.
 , where SO(2) is the set of rotations in Euclidean space. This of course relates to visualizing phase translation as rotation, and seeing phasors as moving in a circle. While SO(2) gives 2D rotational symmetries of a circle, it does not give all symmetries of a circle. That would be the
, where SO(2) is the set of rotations in Euclidean space. This of course relates to visualizing phase translation as rotation, and seeing phasors as moving in a circle. While SO(2) gives 2D rotational symmetries of a circle, it does not give all symmetries of a circle. That would be the 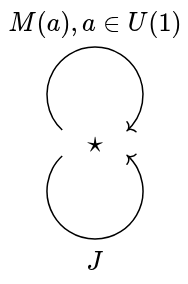
 for complex unitary a, meant to represent a phase translation, and J, meant to represent a distinguished mirroring. We have the following algebraic identities:
for complex unitary a, meant to represent a phase translation, and J, meant to represent a distinguished mirroring. We have the following algebraic identities:


 is an inverse. We can derive that
is an inverse. We can derive that  , so mirroring reverses the way phase translations go, as expected.
, so mirroring reverses the way phase translations go, as expected.![[BO(2), \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BBO%282%29%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , noting the previous correspondence with complex vector spaces, motivates the following definition. A
, noting the previous correspondence with complex vector spaces, motivates the following definition. A  that is an antilinear involution, i.e.:
that is an antilinear involution, i.e.:
 for complex
for complex 

 has a real structure
has a real structure  . So the involution
. So the involution  generalizes complex conjugate.
generalizes complex conjugate.
 , then a linear map
, then a linear map  for all
for all 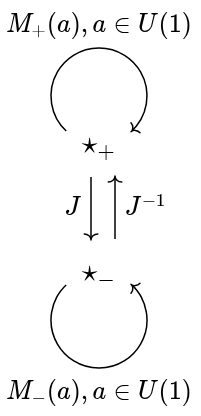
 , which has two objects
, which has two objects  . For complex unitary a, we have morphisms
. For complex unitary a, we have morphisms  and
and  , which compose and invert as usual for U(1). We also have an isomorphism
, which compose and invert as usual for U(1). We also have an isomorphism  satisfying
satisfying  .
.  ). The only essential difference is in separating the two connected components of O(2) into separate objects of the groupoid
). The only essential difference is in separating the two connected components of O(2) into separate objects of the groupoid ![[U(1)_{\pm}, \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BU%281%29_%7B%5Cpm%7D%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . An object of this category picks out two U(1)-symmetric real vector spaces (of which complex vector spaces are an important class), and provides a real-linear isomorphism between them corresponding to J; this isomorphism is not, in general, complex-linear. Importantly, the groupoidal identity
. An object of this category picks out two U(1)-symmetric real vector spaces (of which complex vector spaces are an important class), and provides a real-linear isomorphism between them corresponding to J; this isomorphism is not, in general, complex-linear. Importantly, the groupoidal identity  be a complex vector space with the same elements as V and the same addition function. The only difference is that scalar multiplication is conjugated;
be a complex vector space with the same elements as V and the same addition function. The only difference is that scalar multiplication is conjugated;  . We call
. We call 
 , we write
, we write  for the corresponding vector in the complex conjugate space. Note the following:
for the corresponding vector in the complex conjugate space. Note the following:

 for complex
for complex 
 notation here is not entirely standard (although
notation here is not entirely standard (although  looks like
looks like  , and they are in fact equal.
, and they are in fact equal. as
as  . This definition matches what we would expect from morphisms (natural transformations) in
. This definition matches what we would expect from morphisms (natural transformations) in ![[U(1)_\pm, \mathsf{Vect}_{\mathbb{R}}]](https://s0.wp.com/latex.php?latex=%5BU%281%29_%5Cpm%2C+%5Cmathsf%7BVect%7D_%7B%5Cmathbb%7BR%7D%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . By treating f and
. By treating f and  as separate functions, we avoid the rigidity of σ-linearity.
as separate functions, we avoid the rigidity of σ-linearity. , where
, where 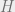 is a Hilbert space (or other complex inner product space). While the inner product is linear in its second argument, it is notoriously anti-linear in its first argument. So while on the one hand
is a Hilbert space (or other complex inner product space). While the inner product is linear in its second argument, it is notoriously anti-linear in its first argument. So while on the one hand  , on the other hand,
, on the other hand,  . Also, the inner product is conjugate symmetric:
. Also, the inner product is conjugate symmetric:  .
. be a quantum state. Now the inner product
be a quantum state. Now the inner product  gives the square of the norm of the state
gives the square of the norm of the state  , as a non-negative real number. If the inner product were bilinear, then we would have
, as a non-negative real number. If the inner product were bilinear, then we would have  . But multiplying
. But multiplying  as expected.
as expected. . The complex conjugate space
. The complex conjugate space  . And we recover conjugate symmetry as
. And we recover conjugate symmetry as  ; the overlines make the conjugate symmetry more intuitive, as we can see parity of conjugation is preserved.
; the overlines make the conjugate symmetry more intuitive, as we can see parity of conjugation is preserved. as a linear map
as a linear map  ; for the inner product, this corresponding map is
; for the inner product, this corresponding map is  . This correspondence motivates studying the complex vector space
. This correspondence motivates studying the complex vector space  .
. . To check:
. To check:
 .
. is notation for a vector in the Hilbert space H. A ‘bra’
is notation for a vector in the Hilbert space H. A ‘bra’  is an element of the dual space of linear functionals of the form
is an element of the dual space of linear functionals of the form  ; this dual space is called
; this dual space is called  . We convert between bras and kets as follows. Given a ket
. We convert between bras and kets as follows. Given a ket  , the corresponding bra is
, the corresponding bra is  , which linearly maps kets to complex numbers. The ket-to-bra mapping is invertible, and antilinear, due to
, which linearly maps kets to complex numbers. The ket-to-bra mapping is invertible, and antilinear, due to  to be linearly, not antilinearly, isomorphic with
to be linearly, not antilinearly, isomorphic with  , we take the partial application
, we take the partial application  . This mapping from
. This mapping from  (note the non-standard notation!). As such,
(note the non-standard notation!). As such,  ; the dual space is isomorphic to the complex conjugate space.
; the dual space is isomorphic to the complex conjugate space. . Because
. Because  , we can see the operator as a linear map
, we can see the operator as a linear map  , or expanded out,
, or expanded out,  . Tensoring up, this is equivalently a linear map
. Tensoring up, this is equivalently a linear map  ; we can see the operator as a quadratic form in a bra and a ket.
; we can see the operator as a quadratic form in a bra and a ket. . We would like to understand real structure on linear operators through real structure on tensored maps of this type. If
. We would like to understand real structure on linear operators through real structure on tensored maps of this type. If  is linear, we define the real structure
is linear, we define the real structure  . As a quick check:
. As a quick check: .
. :
: .
. satisfies
satisfies  ; note
; note  . As such,
. As such,
 . This justifies the Hermitian adjoint as the canonical real structure on the linear operator space
. This justifies the Hermitian adjoint as the canonical real structure on the linear operator space  , as is standard in operator algebra.
, as is standard in operator algebra.

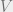 is a Hilbert space, this holds for all
is a Hilbert space, this holds for all  iff
iff  , i.e. A is Hermitian. This is significant, because Hermitians are often used to represent observables (such as in
, i.e. A is Hermitian. This is significant, because Hermitians are often used to represent observables (such as in  with a real structure σ be called self-adjoint iff
with a real structure σ be called self-adjoint iff  . As an important implication of the above, if
. As an important implication of the above, if  is Hermitian, then
is Hermitian, then  , unitary operators are those for which
, unitary operators are those for which  . We will consider time evolution as a family of unitary operators
. We will consider time evolution as a family of unitary operators  for real t, which is group homomorphic as a family (
for real t, which is group homomorphic as a family ( ).
). (for real a). The unitary evolution is given by
(for real a). The unitary evolution is given by  , a multiplicative factor on the phasor to advance it in time. By convention, we have decided that time evolves in the +i direction (multiplicatively), assuming
, a multiplicative factor on the phasor to advance it in time. By convention, we have decided that time evolves in the +i direction (multiplicatively), assuming  . We can find this direction explicitly by differentiating:
. We can find this direction explicitly by differentiating:  .
.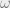 . Interpreting quantum phasors is less straightforward. We can still take the derivative
. Interpreting quantum phasors is less straightforward. We can still take the derivative  , which approximates
, which approximates  as
as  . We recover
. We recover  , which generalizes
, which generalizes  in the single-phasor case.
in the single-phasor case. for Hermitian H; note
for Hermitian H; note  is Hermitian iff H is. In the specific case of the Schrödinger equation,
is Hermitian iff H is. In the specific case of the Schrödinger equation,  where
where  is the
is the  is the reduced Planck constant (a positive real number). The direction of the action of i in quantum state space is meaningful through the Schrödinger convention
is the reduced Planck constant (a positive real number). The direction of the action of i in quantum state space is meaningful through the Schrödinger convention  (as opposed to
(as opposed to  ).
). , while
, while  . In the real structure on linear operator space
. In the real structure on linear operator space  , a Hermitian is self-adjoint, like a real number in
, a Hermitian is self-adjoint, like a real number in  is skew-adjoint (
is skew-adjoint ( ), like an imaginary number in
), like an imaginary number in  for real b).
for real b). (satisfying
(satisfying  ) is anti-linear, due to the relationship between time and phase. In the simpler case,
) is anti-linear, due to the relationship between time and phase. In the simpler case,  , though in systems with half-integer spin,
, though in systems with half-integer spin,  ; see
; see  , the
, the  ; group composition “applies the right element first”. Each channel permutation can be categorized as either being the identity, swapping two channels, or rotating channels in either the red-to-green or green-to-red directions; there are 6 elements of
; group composition “applies the right element first”. Each channel permutation can be categorized as either being the identity, swapping two channels, or rotating channels in either the red-to-green or green-to-red directions; there are 6 elements of ![[S_3, Set]](https://s0.wp.com/latex.php?latex=%5BS_3%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , where
, where  where
where  is group homomorphic in its first argument:
is group homomorphic in its first argument:  and
and  . Since
. Since  is generally clear from context, we also write
is generally clear from context, we also write  as
as  . (Note, p is a
. (Note, p is a  performs a red/green swap on its image argument, like a shader.
performs a red/green swap on its image argument, like a shader. between color qualia spaces
between color qualia spaces  has, for any
has, for any  , the equality
, the equality ![CQS \cong [S_3, Set]](https://s0.wp.com/latex.php?latex=CQS+%5Ccong+%5BS_3%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) . Let’s quickly list some examples of equivariant maps:
. Let’s quickly list some examples of equivariant maps: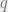 to
to  for a non-trivial
for a non-trivial 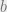 , i.e. swapping two channels, or rotating channels.
, i.e. swapping two channels, or rotating channels. is a function on images. Now to check equivariance, we ask if
is a function on images. Now to check equivariance, we ask if  . But this is only true when
. But this is only true when  , the group identity. Note
, the group identity. Note  is the set of elements reachable through group actions,
is the set of elements reachable through group actions,  . Now let the orbit map
. Now let the orbit map  map elements to their orbits, effectively quotienting over channel permutations. The orbit map relates to equivariance in the following way: for any equivariant
map elements to their orbits, effectively quotienting over channel permutations. The orbit map relates to equivariance in the following way: for any equivariant  commuting,
commuting,  .
.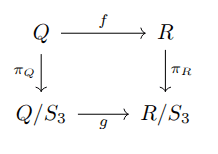
 must map elements of a single Q-orbit to a single R-orbit, which allows defining
must map elements of a single Q-orbit to a single R-orbit, which allows defining 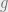 commuting. Any alternative choice would fail commutation on some Q-orbit.)
commuting. Any alternative choice would fail commutation on some Q-orbit.) has elements
has elements  ; it is trivial.
; it is trivial. has elements
has elements  representing chirality. Channel reflections (RBG, GRB, BGR) flip chirality, rotations preserve it. (Imagine three balls corresponding to primary colors, with sticks connecting them in a triangle; chirality-reversing operations require flipping the triangle over vertically.)
representing chirality. Channel reflections (RBG, GRB, BGR) flip chirality, rotations preserve it. (Imagine three balls corresponding to primary colors, with sticks connecting them in a triangle; chirality-reversing operations require flipping the triangle over vertically.) has elements {R, B, G} representing primary colors. Group operations work straightforwardly, e.g.
has elements {R, B, G} representing primary colors. Group operations work straightforwardly, e.g.  .
. has as elements total orderings of primary colors (e.g. R > B > G), of which there are 6. Group operations work straightforwardly, e.g.
has as elements total orderings of primary colors (e.g. R > B > G), of which there are 6. Group operations work straightforwardly, e.g.  .
. to only 9 realizable signatures. 4 of these signatures are clearly trivial, as they map to
to only 9 realizable signatures. 4 of these signatures are clearly trivial, as they map to  : identity and chirality-reversal.
: identity and chirality-reversal. , the identity.
, the identity. , which assign distinct chiralities to the two cyclic orbits, {(R > G > B), (B > R > G), (G > B > R)} and {(B > G > R), (R > B > G), (G > R > B)}.
, which assign distinct chiralities to the two cyclic orbits, {(R > G > B), (B > R > G), (G > B > R)} and {(B > G > R), (R > B > G), (G > R > B)}. , which pick out either the greatest, middle, or least primary color.
, which pick out either the greatest, middle, or least primary color. corresponding to each of the
corresponding to each of the  are as follows:
are as follows: , determine how
, determine how  , which has a finite combinatorial characterization.
, which has a finite combinatorial characterization.
 is the set of equivariant maps between color qualia spaces S and T, and
is the set of equivariant maps between color qualia spaces S and T, and  are set-theoretic dependent product and sum.
are set-theoretic dependent product and sum.![[O(2), Set]](https://s0.wp.com/latex.php?latex=%5BO%282%29%2C+Set%5D&bg=eeeeee&fg=666666&s=0&c=20201002) .)
.) . A vector space has addition, zero, and scalar multiplication defined, which have the standard commutativity/associativity/distributivity properties. The category
. A vector space has addition, zero, and scalar multiplication defined, which have the standard commutativity/associativity/distributivity properties. The category  has as objects vector spaces (over the field
has as objects vector spaces (over the field  and
and  . (Advanced readers may see
. (Advanced readers may see  , which has as elements pairs (u, v) with
, which has as elements pairs (u, v) with  , and for which addition and scalar multiplication are element-wise, is also a vector space. The direct sum is both a product and a coproduct.
, and for which addition and scalar multiplication are element-wise, is also a vector space. The direct sum is both a product and a coproduct. and
and  be the projections of the direct sum onto its elements. Let us suppose a third vector space T and linear maps
be the projections of the direct sum onto its elements. Let us suppose a third vector space T and linear maps  and
and  . Let
. Let  be defined as
be defined as  . Now
. Now  uniquely commutes:
uniquely commutes:
 be defined as
be defined as  , and similarly let
, and similarly let  be defined as
be defined as  . Let us suppose a third vector space W and linear maps
. Let us suppose a third vector space W and linear maps  and
and  . Let
. Let ![[f, g] : U \oplus V \rightarrow W](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D+%3A+U+%5Coplus+V+%5Crightarrow+W&bg=eeeeee&fg=666666&s=0&c=20201002) be defined as
be defined as  = f(u) + g(v)](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D%28u%2C+v%29+%3D+f%28u%29+%2B+g%28v%29&bg=eeeeee&fg=666666&s=0&c=20201002) . Now
. Now ![[f, g]](https://s0.wp.com/latex.php?latex=%5Bf%2C+g%5D&bg=eeeeee&fg=666666&s=0&c=20201002) uniquely commutes:
uniquely commutes:
 be a zero function; since the direct sum also satisfies the identities
be a zero function; since the direct sum also satisfies the identities  , by definition it is a
, by definition it is a  .
. (in C), we may uniquely decompose it as
(in C), we may uniquely decompose it as  for some
for some  . And similarly, we may uniquely decompose
. And similarly, we may uniquely decompose  as
as ![h = [f, g]](https://s0.wp.com/latex.php?latex=h+%3D+%5Bf%2C+g%5D&bg=eeeeee&fg=666666&s=0&c=20201002) for some
for some  .
. is an object for natural
is an object for natural  . Now the n-ary biproduct is
. Now the n-ary biproduct is  . We take the empty biproduct to be 0. We can also generalize the projections
. We take the empty biproduct to be 0. We can also generalize the projections  , the injections
, the injections  , the “row-wise” combination
, the “row-wise” combination  be objects in C, for natural
be objects in C, for natural  and
and  . Suppose
. Suppose  . We first decompose h “row-wise”, as
. We first decompose h “row-wise”, as  where
where  . Then we decompose each row “column-wise”, as
. Then we decompose each row “column-wise”, as ![h_j = [h_{j,1}, \ldots, h_{j,m}]](https://s0.wp.com/latex.php?latex=h_j+%3D+%5Bh_%7Bj%2C1%7D%2C+%5Cldots%2C+h_%7Bj%2Cm%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) where
where  . We can now write h in matrix style, as
. We can now write h in matrix style, as ![h = \langle [ h_{1, 1}, \ldots, h_{1, m} ], \ldots, [h_{n, 1}, \ldots, h_{n, m}] \rangle](https://s0.wp.com/latex.php?latex=h+%3D+%5Clangle+%5B+h_%7B1%2C+1%7D%2C+%5Cldots%2C+h_%7B1%2C+m%7D+%5D%2C+%5Cldots%2C+%5Bh_%7Bn%2C+1%7D%2C+%5Cldots%2C+h_%7Bn%2C+m%7D%5D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) ; the notation
; the notation  can be visualized as vertical matrix concatenation, and
can be visualized as vertical matrix concatenation, and ![[ \ldots ]](https://s0.wp.com/latex.php?latex=%5B+%5Cldots+%5D&bg=eeeeee&fg=666666&s=0&c=20201002) can be visualized as horizontal matrix concatenation.
can be visualized as horizontal matrix concatenation.
 . Now a map
. Now a map  decomposes as a
decomposes as a  matrix of linear maps
matrix of linear maps  . This is not quite a traditional matrix, but note that linear maps of type
. This is not quite a traditional matrix, but note that linear maps of type  are always multiplication by a constant real slope. Representing each
are always multiplication by a constant real slope. Representing each  by its slope yields a more traditional numeric matrix.
by its slope yields a more traditional numeric matrix. for some natural n. Specifically, if a space U has a basis
for some natural n. Specifically, if a space U has a basis  , then the linear map
, then the linear map  defined as
defined as  is an isomorphism. Hence, matrix representation extends to maps between finite-dimensional vector spaces.
is an isomorphism. Hence, matrix representation extends to maps between finite-dimensional vector spaces. be natural, and let
be natural, and let  be objects in C (for naturals
be objects in C (for naturals  ). Suppose we have maps
). Suppose we have maps  and
and  . We can write f in matrix form (
. We can write f in matrix form ( ), and similarly g (
), and similarly g ( ).
).
 . We fix i, k and consider the entry
. We fix i, k and consider the entry  . Now note
. Now note ![\pi_k \circ g = [g_{k, 1}, \ldots, g_{k, n}]](https://s0.wp.com/latex.php?latex=%5Cpi_k+%5Ccirc+g+%3D+%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002) and
and  . Therefore
. Therefore![h_{k, i} = [g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle](https://s0.wp.com/latex.php?latex=h_%7Bk%2C+i%7D+%3D+%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002)

 in
in  can also be written:
can also be written:
![[g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle = \sum_{j=1}^n (g_{k, j} \circ f_{j, i})](https://s0.wp.com/latex.php?latex=%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle+%3D+%5Csum_%7Bj%3D1%7D%5En+%28g_%7Bk%2C+j%7D+%5Ccirc+f_%7Bj%2C+i%7D%29&bg=eeeeee&fg=666666&s=0&c=20201002) to semiadditive categories in general; for details, see
to semiadditive categories in general; for details, see ![\langle [h_{1, 1}, \ldots, h_{1, m}], \ldots, [h_{n, 1}, \ldots, h_{n, m}] \rangle](https://s0.wp.com/latex.php?latex=%5Clangle+%5Bh_%7B1%2C+1%7D%2C+%5Cldots%2C+h_%7B1%2C+m%7D%5D%2C+%5Cldots%2C+%5Bh_%7Bn%2C+1%7D%2C+%5Cldots%2C+h_%7Bn%2C+m%7D%5D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) with
with  .
.![[g_{k, 1}, \ldots, g_{k, n}] \circ \langle f_{1, i}, \ldots, f_{n, i} \rangle](https://s0.wp.com/latex.php?latex=%5Bg_%7Bk%2C+1%7D%2C+%5Cldots%2C+g_%7Bk%2C+n%7D%5D+%5Ccirc+%5Clangle+f_%7B1%2C+i%7D%2C+%5Cldots%2C+f_%7Bn%2C+i%7D+%5Crangle&bg=eeeeee&fg=666666&s=0&c=20201002) .
. , or is at least isomorphic. Solomonoff induction, and similarly the speed prior, posit that reality consists of an input to a universal Turing machine (specifying some other Turing machine and its input), and its execution trajectory, producing digital subjective experience.
, or is at least isomorphic. Solomonoff induction, and similarly the speed prior, posit that reality consists of an input to a universal Turing machine (specifying some other Turing machine and its input), and its execution trajectory, producing digital subjective experience. specify the universe’s physical state as a function of the reality state. Let
specify the universe’s physical state as a function of the reality state. Let  specify the universe’s mental state as a function of the reality state. These presumably exist under the above assumptions, because physics and mind are both aspects of reality, though these need not be efficiently computable functions. (The general structure of physics and mind being aspects of reality is inspired by neutral monism, though it does not necessitate neutral monism.)
specify the universe’s mental state as a function of the reality state. These presumably exist under the above assumptions, because physics and mind are both aspects of reality, though these need not be efficiently computable functions. (The general structure of physics and mind being aspects of reality is inspired by neutral monism, though it does not necessitate neutral monism.)
 means “there exists a unique”.
means “there exists a unique”.
 commuting (
commuting ( ), though again, h need not be efficiently computable.
), though again, h need not be efficiently computable. , specifically, that we do not exist in a digital computer simulation. While I don’t accept the simulation hypothesis as likely, it seems presumptuous to reject it on philosophy of mind grounds.
, specifically, that we do not exist in a digital computer simulation. While I don’t accept the simulation hypothesis as likely, it seems presumptuous to reject it on philosophy of mind grounds. as the mainline model. (Note that Chalmers believes natural supervenience holds but that strict physicalism is false.)
as the mainline model. (Note that Chalmers believes natural supervenience holds but that strict physicalism is false.) being the initial state. A value function on states satisfies:
being the initial state. A value function on states satisfies:
 and
and  respectively. To state a no P-evildoers principle:
respectively. To state a no P-evildoers principle:

 be arbitrary. Either there is some possible world with this physical trajectory, or not. If not, we can let
be arbitrary. Either there is some possible world with this physical trajectory, or not. If not, we can let  be arbitrary, and
be arbitrary, and  will hold vacuously.
will hold vacuously. be some such world and set
be some such world and set  . Now consider some arbitrary possible world w for which
. Now consider some arbitrary possible world w for which  . Either it is true that
. Either it is true that  or not. If it is, we are done; we have that
or not. If it is, we are done; we have that  . If not, then observe that w and
. If not, then observe that w and  . The axioms of
. The axioms of 