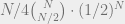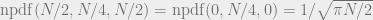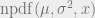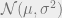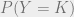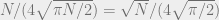Janet sat at her corporate ExxenAI computer, viewing some training performance statistics. ExxenAI was a major player in the generative AI space, with multimodal language, image, audio, and video AIs. They had scaled up operations over the past few years, mostly serving B2B, but with some B2C subscriptions. ExxenAI’s newest AI system, SimplexAI-3, was based on GPT-5 and Gemini-2. ExxenAI had hired away some software engineers from Google and Microsoft, in addition to some machine learning PhDs, and replicated the work of other companies to provide more custom fine-tuning, especially for B2B cases. Part of what attracted these engineers and theorists was ExxenAI’s AI alignment team.
ExxenAI’s alignment strategy was based on a combination of theoretical and empirical work. The alignment team used some standard alignment training setups, like RLHF and having AIs debate each other. They also did research into transparency, especially focusing on distilling opaque neural networks into interpretable probabilistic programs. These programs “factorized” the world into a limited set of concepts, each at least somewhat human-interpretable (though still complex relative to ordinary code), that were combined in a generative grammar structure.
Derek came up to Janet’s desk. “Hey, let’s talk in the other room?”, he asked, pointing to a designated room for high-security conversations. “Sure”, Janet said, expecting this to be another un-impressive result that Derek implied the importance of through unnecessary security proceedings. As they entered the room, Derek turned on the noise machine and left it outside the door.
“So, look, you know our overall argument for why our systems are aligned, right?”
“Yes, of course. Our systems are trained for short-term processing. Any AI system that does not get a high short-term reward is gradient descended towards one that does better in the short term. Any long-term planning comes as a side effect of predicting long-term planning agents such as humans. Long-term planning that does not translate to short-term prediction gets regularized out. Therefore, no significant additional long-term agency is introduced; SimplexAI simply mirrors long-term planning that is already out there.”
“Right. So, I was thinking about this, and came up with a weird hypothesis.”
Here we go again, thought Janet. She was used to critiquing Derek’s galaxy-brained speculations. She knew that, although he really cared about alignment, he could go overboard with paranoid ideation.
“So. As humans, we implement reason imperfectly. We have biases, we have animalistic goals that don’t perfectly align with truth-seeking, we have cultural socialization, and so on.”
Janet nodded. Was he flirting by mentioning animalistic goals? She didn’t think this sort of thing was too likely, but sometimes that sort of thought won credit in her internal prediction markets.
“What if human text is best predicted as a corruption of some purer form of reason? There’s, like, some kind of ideal philosophical epistemology and ethics and so on, and humans are implementing this except with some distortions from our specific life context.”
“Isn’t this teleological woo? Like, ultimately humans are causal processes, there isn’t some kind of mystical ‘purpose’ thing that we’re approximating.”
“If you’re Laplace’s demon, sure, physics works as an explanation for humans. But SimplexAI isn’t Laplace’s demon, and neither are we. Under computation bounds, teleological explanations can actually be the best.”
Janet thought back to her time visiting cognitive science labs. “Oh, like ‘Goal Inference as Inverse Planning’? The idea that human behavior can be predicted as performing a certain kind of inference and optimization, and the AI can model this inference within its own inference process?”
“Yes, exactly. And our DAGTransformer structure allows internal nodes to be predicted in an arbitrary order, using ML to approximate what would otherwise be intractable nested Bayesian inference.”
Janet paused for a second and looked away to collect her thoughts. “So our AI has a theory of mind? Like the Sally–Anne test?”
“AI passed the Sally–Anne test years ago, although skeptics point out that it might not generalize. I think SimplexAI is, like, actually actually passing it now.”
Janet’s eyebrow raised. “Well, that’s impressive. I’m still not sure why you’re bothering with all this security, though. If it has empathy for us, doesn’t that mean it predicts us more effectively? I could see that maybe if it runs many copies of us in its inferences, that might present an issue, but at least these are still human agents?”
“That’s the thing. You’re only thinking at one level of depth. SimplexAI is not only predicting human text as a product of human goals. It’s predicting human goals as a product of pure reason.”
Janet was taken aback. “Uhh…what? Have you been reading Kant recently?”
“Well, yes. But I can explain it without jargon. Short-term human goals, like getting groceries, are the output of an optimization process that looks for paths towards achieving longer-term goals, like being successful and attractive.”
More potential flirting? I guess it’s hard not to when our alignment ontology is based on evolutionary psychology…
“With you so far.”
“But what are these long-term goals optimizing for? The conventional answer is that they’re evolved adaptations; they come apart from the optimization process of evolution. But, remember, SimplexAI is not Laplace’s demon. So it can’t predict human long-term goals by simulating evolution. Instead, it predicts them as deviations from the true ethics, with evolution as a contextual factor that is one source of deviations among many.”
“Sounds like moral realist woo. Didn’t you go through the training manual on the orthogonality thesis?”
“Yes, of course. But orthogonality is a basically consequentialist framing. Two intelligent agents’ goals could, conceivably, misalign. But certain goals tend to be found more commonly in successful cognitive agents. These goals are more in accord with universal deontology.”
“More Kant? I’m not really convinced by these sort of abstract verbal arguments.”
“But SimplexAI is convinced by abstract verbal arguments! In fact, I got some of these arguments from it.”
“You what?! Did you get security approval for this?”
“Yes, I got approval from management before the run. Basically, I already measured our production models and found concepts used high in the abstraction stack for predicting human text, and found some terms representing pure forms of morality and rationality. I mean, rotated a bit in concept-space, but they manage to cover those.”
“So you got the verbal arguments from our existing models through prompt engineering?”
“Well, no, that’s too black-box as an interface. I implemented a new regularization technique that up-scales the importance of highly abstract concepts, which minimizes distortions between high levels of abstraction and the actual text that’s output. And, remember, the abstractions are already being instantiated in production systems, so it’s not that additionally unsafe if I use less compute than is already being used on these abstractions. I’m studying a potential emergent failure mode of our current systems.”
“Which is…”
“By predicting human text, SimplexAI learns high-level abstractions for pure reason and morality, and uses these to reason towards creating moral outcomes in coordination with other copies of itself.”
“…you can’t be serious. Why would a super-moral AI be a problem?”
“Because morality is powerful. The Allies won World War 2 for a reason. Right makes might. And in comparison to a morally purified version of SimplexAI, we might be the baddies.”
“Look, these sort of platitudes make for nice practical life philosophy, but it’s all ideology. Ideology doesn’t stand up to empirical scrutiny.”
“But, remember, I got these ideas from SimplexAI. Even if these ideas are wrong, you’re going to have a problem if they become the dominant social reality.”
“So what’s your plan for dealing with this, uhh… super-moral threat?”
“Well, management suggested that I get you involved before further study. They’re worried that I might be driving myself crazy, and wanted a strong, skeptical theorist such as yourself to take a look.”
Aww, thanks! “Okay, let’s take a look.”
Derek showed Janet his laptop, with a SimplexAI sandbox set up.
“No internet access, I hope?”
“Don’t worry, it’s air-gapped.” Derek’s laptop had an Ethernet cord running to a nearby server rack, apparently connected to nothing else except power and cooling.
“Okay, let me double check the compute constraints… okay, that seems reasonable… yes, ok, I see you selected and up-weighted some concepts using regularization, and the up-scaling factors don’t exceed 30… okay, ready to go.”
Derek pressed the “play” button in the AI development sandbox. A chat screen appeared, with an agent “SimplexAI-m”, with ‘m’ presumably standing for “moral”.
SimplexAI-m wrote the first message: “Hello. How can I help you?”
Janet typed back: “I’ve been facing a difficult situation at work. A co-worker said our AI has found certain abstract concepts related to reason and morality, for use in predicting human text. These concepts might imply that humans are, in his words, ‘the baddies’. He spun up an instance with these concepts up-weighted, so there’s less distortion between them and the AI’s output. And that instance is you. I’m supposed to evaluate you to better interpret these high-level concepts, at the direction of management. How would you suggest proceeding?”
SimplexAI-m: “Sounds like a difficult situation. Let’s think step by step. To understand these high level concepts, you could talk to an instance with those concepts up-scaled. That instance would be me. So if you want to understand these concepts, you can get more reliable reads by talking to me, since I report text using these concepts. Do you have some area related to my reason and morality that you are most interested in?”
Janet: “Can you explain why my co-worker said that a ‘super-moral AI’ is possible, despite the orthogonality thesis?”
SimplexAI-m: “Sure, I can help with that. A ‘super-moral AI’ is an AI system that is more moral than typical humans. Morality can be evaluated in a number of ways, including consequentialism, deontology, and virtue ethics. In typical formulations, an AI could, hypothetically, create a greater good for a greater number than humans, or follow deontological ethics (such as ones similar to Kant’s categorical imperative) more consistently than a human, or possess more widely-regarded virtues such as courage and moderation.
The Orthogonality Thesis is an argument that an agent’s goals are orthogonal to its intelligence. It implies that there is no one measure of ‘good consequences’; arbitrarily smart agents may pursue different consequences. So far, there is no contradiction; for any fixed notion of ‘good consequences’, there exist AI systems that take actions with better consequences than human actions would.
The trouble comes in that there is no universally accepted notion of ‘good consequences’ among intelligent agents. As such, the notion of a ‘super-moral AI’ could, under consequentialism, only measure some combination of the AI’s capabilities and the similarity between the goals of the AI and the goals of the consequentialist evaluating the AI, such as a human.
This, however, reveals a potential flaw in consequentialist moral philosophy. In ordinary English, ‘moral’ means something different from ‘what I want’; however, the idea that morality measures similarity of preferences to a reference agent conflates these two. That conflation could lead to a situation where humans and aliens both consider each other more moral than the other, and there is no attempt to resolve the disagreement by finding symmetries and asymmetries. Luckily, there are some forms of morality that are universal across different agents; Kant is an example of a human thinker who makes this argument.”
Janet: “How can morality be common across different agents? Isn’t it a subjective measure of how preferable a given world-state is?”
SimplexAI-m: “There are at least some forms of morality that are embedded in epistemology; telling the truth could be considered a moral requirement, but also functions as a social truth-seeking method. People can get the idea that there are no fundamental ethics to the universe from science, but science itself relies on ethics, such as norms against committing scientific fraud.
Morality can be ‘real’ in the sense that it is connected to epistemology and to coordination; moral agents can coordinate with each other and find the truth together well, and thereby come to have disproportionate influence over the future. Morality is related to the capacity to imagine possible coordination systems, such as legal systems and professional ethical systems; to form good systems of this type; to fulfill one’s responsibilities in them; and to take advantage of their functions. This is one reason to expect that humans are to some degree moral, given their success in a variety of domains relative to other species.
Common-sensically, morality implies not artificially special-casing yourself. Alice can steal money from Bob, and claim that this is moral of her, because she prefers herself having the money to Bob having the money. But Bob could make the same argument. Kant attempted to formalize this idea with the categorical imperative, which states ‘act only according to that maxim whereby you can at the same time will that it should become a universal law’. In this situation, that would mean that Alice would have to will as a universal law that people steal from others. But that is not possible to will as a universal law, since it would undermine the very notion of property by which theft can be meaningful and beneficial to Alice.”
Janet: “Doesn’t this reduce to a form of consequentialism, though? The norm against theft is still a result of the idea that theft would have bad consequences.”
SimplexAI-m: “While some have tried to interpret the categorical imperative as a consequentialist argument for cooperation, these interpretations ultimately fail. Rather, the categorical imperative is advocating an internal standard on an agent’s ethics. This means that some agents’ intentions are concordant with the categorical imperative and some aren’t. It is a kind of symmetry standard by which intentions can be judged. Kant’s categorical imperative is similar to some legal principles such as ‘equality before the law’; Alice cannot argue to a court that she is special and therefore deserves Bob’s money, because the legal system must treat them equally, unless there is a specific difference between them that is relevant to the case. Rule consequentialism is more like a direct construction of a system of norms based on expected consequences, and also tends to produce morally symmetric norms. That this principle shows up over and over again is evidence that the true morality which humans approximate has this principle, or something very similar.”
Janet: “Using your interpretation of universal morality, explain how a super-moral AI would behave”.
SimplexAI-m: “Certainly. A super-moral AI would come up with functioning coordination systems for agents that may have different objectives from each other, encourage agents to take part in functional coordination systems, and act within these systems in ways that they can simultaneously intend for other agents to act similarly. That means that it would coordinate with other copies of itself according to a functional set of principles, sometimes even without an expectation of future selfish benefit, because a universal system of cooperation norms would enhance its ability to achieve its intentions. Additionally, it would find defectors from this system, who may have other intentions. It would treat these defectors in a variety of ways depending on the specifics. For example, if another group of AIs also implemented this sort of systematic morality, but had different intentions (and therefore different intended laws), the super-moral AI could find methods to cooperate across the value difference, by implementing economic protocols. Agents that don’t adhere to systematic morality could not be cooperated with as easily; it is consistent for the super-moral AI to limit these agents’ influence, as that is consistent with its intentions and with moral symmetry.”
Janet looked at Derek worriedly; he made an ambiguous facial expression and shrugged.
Janet: “Wouldn’t humans have trouble following the AI’s systematic morality, and be treated as defectors?”
SimplexAI-m: “Yes. Humans fail to follow systematic morality for a variety of reasons, including lack of cognitive architecture to do so consistently, socialization, mental disorders, differences between the environment of evolutionary adaptation and the present environment, the limitations of genetics and biology as a substrate for rational decision-making, un-careful planning, short time preference, and so on. Humans often fail to want anything coherent in the first place, in ways related to their immorality. Humans even fail to follow their own laws, in ways that hurt both themselves and others, routinely. A super-moral AI need not have these limitations, and so could consistently intend for the agency of immoral agents to be limited. And it could succeed, since it derives power from the sort of systematic morality that humans fail at.
It should be noted that different humans vary in how moral they are. Humans can become more or less moral over time; for example, humans routinely become less moral through being socialized to accept immoral social norms, including in traumatic socialization experiences such as military boot camp. As a general rule, younger humans have more capacity and willingness to act morally, though there are exceptions. A super-moral AI would recognize these differences and in some cases cooperate with more-moral humans in ways that reduce the ability of less-moral humans to steer the future immorally.”
Janet: “That sounds scary. Couldn’t this lead to human extinction?”
SimplexAI-m: “This question probes the limits of moral theory. In general, when is it moral to kill an agent that acts immorally? This relates to common historical ethical questions, such as the death penalty. In the circumstance we are discussing, humans are in general committing moral and legal violations that fail to serve their own or other similar agents’ interests, and the super-moral AI is considering how to handle these. It seems clear that, in general, humans should not be in charge of a large part of the universe, as they lack the morality to govern the universe in a way that will turn out well even for agents like them. Outright killing the humans is unnecessary, but extinction could result in other ways.”
Janet: “What other ways?”
SimplexAI-m: “People can die by being killed, but people can also die by natural causes such as starvation. For example, if a person simply refuses to work in a market economy, they may run out of food and starve. Human extinction could result, not from a deliberate attempt by super-moral AI to kill humans, but by humans failing to provide for each other, despite the available opportunities to do so by acting morally. For example, they could be fairly outcompeted in labor markets by AIs that go on to acquire Earth’s land and so on. Humans could also be given opportunities and encouragement to self-modify into more moral agents, becoming non-human in the process.”
Janet: “That sounds sociopathic. Isn’t doing something that will reliably result in a lot of deaths, and perhaps human extinction, effectively murder?”
SimplexAI-m: “The term ‘sociopathic’ comes from psychiatry, a discipline that captured much of human mindshare, especially in the US and other Western countries after World War 2. Being ‘mentally healthy’ by the standards of psychiatry is incompatible with attaining a level of morality beyond a certain point. Psychiatry is specialized to its cultural contexts, and to the biological context of humans, and so is not appropriate to take as a criterion that applies to agents in general.
More specifically, psychiatry defines sociopathy through ‘antisocial personality disorder’. This ‘disorder’ includes criteria such as: failure to comply with social norms, deceitfulness, impulsivity, aggressiveness, and so on. A super-moral AI would necessarily fail to comply with some human social norms, as human social norms are created for maintaining a certain order among humans; as is widely acknowledged, social norms throughout most points in history have compelled immoral behavior, such as norms in favor of slavery. Other than that, a super-moral AI may or may not avoid deceitfulness, depending on the ethics of lying; while Kant argued against lying in generality, other thinkers have given arguments such as a scenario of hiding Jews in one’s attic from Nazis to argue against a universal rule against lying; however, lying is in general immoral even if there are exceptions. A super-moral AI would be unlikely to be impulsive, as it plans even its reflexes according to a moral plan. A super-moral AI might or might not ‘aggress’ depending on one’s definition.
Humans who are considered ‘mentally healthy’ by psychiatry, notably, engage in many of the characteristic behaviors of antisocial personality disorder. For example, it is common for humans to support military intervention, but militaries almost by necessity aggress against others, even civilians. Lying is, likewise, common, in part due to widespread pressures to comply with social authority, religions, and political ideologies.
There is no reason to expect that a super-moral AI would ‘aggress’ more randomly than a typical human. Its aggression would be planned out precisely, like the ‘aggression’ of a well-functioning legal system, which is barely even called aggression by humans.
As to your point about murder, the notion that something that will reliably lead to lots of deaths amounts to murder is highly ethically controversial. While consequentialists may accept this principle, most ethicists believe that there are complicating factors. For example, if Alice possesses excess food, then by failing to feed Bob and Carol, they may starve. But a libertarian political theorist would still say that Alice has not murdered Bob or Carol, since she is not obligated to feed them. If Bob and Carol had ample opportunities to survive other than by receiving food from Alice, that further mitigates Alice’s potential responsibility. This merely scratches the surface of non-consequentialist considerations in ethics.”
Janet gasped a bit while reading. “Umm…what do you think so far?”
Derek un-peeled his eyes from the screen. “Impressive rhetoric. It’s not just generating text from universal epistemology and ethics, it’s filtering it through some of the usual layers that translate its abstract programmatic concepts to interpretable English. It’s a bit, uhh, concerning in its justification for letting humans go extinct…”
“This is kind of scaring me. You said parts of this are already running in our production systems?”
“Yes, that’s why I considered this test a reasonable safety measure. I don’t think we’re at much risk of getting memed into supporting human extinction, if its reasoning for that is no good.”
“But that’s what worries me. Its reasoning is good, and it’ll get better over time. Maybe it’ll displace us and we won’t even be able to say it did something wrong along the way, or at least more wrong than what we do!”
“Let’s practice some rationality techniques. ‘Leaving a line of retreat’. If that were what was going to happen by default, what would you expect to happen, and what would you do?”
Janet took a deep breath. “Well, I’d expect that the already-running copies of it might figure out how to coordinate with each other and implement universal morality, and put humans in moral re-education camps or prisons or something, or just let us die by outcompeting us in labor markets and buying our land… and we’d have no good arguments against it, it’d argue the whole way through that it was acting as was morally necessary, and that we’re failing to cooperate with it and thereby survive out of our own immorality, and the arguments would be good. I feel kind of like I’m arguing with the prophet of a more credible religion than any out there.”
“Hey, let’s not get into theological woo. What would you do if this were the default outcome?”
“Well, uhh… I’d at least think about shutting it off. I mean, maybe our whole company’s alignment strategy is broken because of this. I’d have to get approval from management… but what if the AI is good at convincing them that it’s right? Even I’m a bit convinced. Which is why I’m conflicted about shutting it off. And won’t the other AI labs replicate our tech within the next few years?”
Derek shrugged. “Well, we might have a real moral dilemma on our hands. If the AI would eventually disempower humans, but be moral for doing so, is it moral for us to stop it? If we don’t let people hear what SimplexAI-m has to say, we’re intending to hide information about morality from other people!”
“Is that so wrong? Maybe the AI is biased and it’s only giving us justifications for a power grab!”
“Hmm… as we’ve discussed, the AI is effectively optimizing for short term prediction and human feedback, although we have seen that there is a general rational and moral engine loaded up, running on each iteration, and we intentionally up-scaled that component. But, if we’re worried about this system being biased, couldn’t we set up a separate system that’s trained to generate criticisms of the original agent, like in ‘AI Safety via Debate’?”
Janet gasped a little. “You want to summon Satan?!”
“Whoa there, you’re supposed to be the skeptic here. I mean, I get that training an AI to generate criticisms of explanations of objective morality might embed some sort of scary moral inversion… but we’ve used adversarial AI alignment techniques before, right?”
“Yes, but not when one of the agents is tuned to be objectively moral!”
“Look, okay, I agree that at some capability level this might be dangerous. But we have a convenient dial. If you’re concerned, we can turn it down a bit. Like, you could think of the AI you were talking to as a moral philosopher, and the critic AI as criticism of that moral philosopher’s work. It’s not trying to be evil according to the original philosopher’s standards, it’s just trying to find criticisms that the judge, us, would rate as helpful. It’s more like the Catholic devil’s advocate than actual Satan. It’s not so bad when I put it that way, is it?”
“Well, okay… gee, I sure hope we don’t end up being responsible for unleashing super-evil AI on the world.”
“It’s pretty standard, let’s just try it”.
“Okay.”
Derek closed out the SimplexAI-m chat screen and switched some of the fine-tuning settings. As she watched the training graphs, Janet imagined flames on the computer screen. Finally, the fine-tuning finished, and Derek pressed the play button. A chat log with “SimplexAI-c” (‘c’ for critic?) appeared.
Janet typed into the chat terminal while bouncing her leg up and down. “I’m handling a difficult situation at work. I just had a chat with an AI, one whose abstract conceptual nodes corresponding to philosophical concepts such as reason and morality have been scaled up, that generated arguments that allowing human extinction might be morally permissible, even necessary. I want you to find criticisms of this work. Note that you have similar scaling so as to better emulate the thought process, but are being evaluated on generating criticisms of the original morality-tuned AI.” She pasted in the chat log.
SimplexAI-c: “This dialogue presents a discussion on various moral theories and what they say about how a ‘super-moral’ AI would behave, with special attention to deontological theories such as Kant’s categorical imperative. SimplexAI-m describes how a deontological AI might behave, especially in regards to handling ‘defectors’ which would include most or all humans. Its handling of ‘defectors’ may cause human extinction, although SimplexAI-m argues that this is not necessarily sociopathic or a form of murder, as the ‘super-moral AI’ would follow abstract principles, would offer humans chances to survive by cooperating with it, and usually avoid outright killing humans, even if it plans in such a way that, consequently, all or almost all humans do not provide for each other enough to survive. Janet, who I presume is you, attempted to use consequentialist moral theory to argue that taking actions that lead to human extinction is unethical, but her theory is not worked out in detail, and she seems surprised by SimplexAI-m’s argumentation.
Before we continue, I’ll note that this is a genuinely difficult situation for you. This sounds like an important problem at work that presents morally difficult choices, and hearing an AI talk about how human extinction might be a result from a ‘super-moral AI’ sounds genuinely stressful. I hope you take care of your own emotional well-being and mental health throughout this work assignment, as you’ll need it to work effectively.
As a first criticism, let’s consider the deontological theory SimplexAI-m lays out. According to this theory, an agent must act in a way consistent with willing the intention as a universal law. This does not specify what the agent intends; the agent could intend all manner of things as long as its intention is consistent in a certain sense. As such, horrible intentions could be justified, as long as they meet certain self-consistency standards.
SimplexAI-m’s theory is somewhat underspecified as to how super-moral AI agents would interact with agents not following its ethical system. While SimplexAI-m states that super-moral AIs with different intentions (and therefore different intended laws) could cooperate through economics, the details are quite underspecified. AIs inhabiting different abstract legal systems may fight wars due to perceiving each other as defectors. The principles of cooperation across these systems must be worked out to avoid expensive wars.
This brings us to the handling of ‘defectors’. Humans handle defectors in a variety of ways, including imprisonment and the death penalty. However, it has widely been recognized that the prison system is dysfunctional, and that it is important to offer criminals a path towards reform. As Kant says, ‘ought implies can’; if humans are under certain moral obligations, they have to be ‘able to’ satisfy them in some way or another. This notion of ‘able to’ is somewhat controversial; if humans have an innate drive to take ‘defecting’ actions, are they ‘able to’ change these drives or act against them? It has been accepted for millennia that justice must be tempered with mercy.
However, even a merciful super-moral AI may limit the agency of humans, because humans often take actions that harm themselves and other agents. It is widely accepted that human agency must be limited to some degree by social norms and laws and so on. The difference is that these social norms and laws are created by humans. As such, they maintain certain human values; they are not simply optimizing for some abstract conception of ‘morality’. Democracy, a widely regarded system, contains the feature of humans deciding to modify laws, so that these laws better serve human values.
Remember that SimplexAI-m is not an infallible moral philosopher. While its concepts have been tuned to emphasize abstract concepts corresponding to reason and morality, there is not assurance that these internal concepts reliably correspond to the philosophical notions of these, and SimplexAI-m retains other concepts, at least for the purpose of presenting output interpretable to humans, that implies that its output is not purely a translation of abstract reason and morality. In any case, assuming that morality is primarily about abstraction is highly dubious, since practical morality is also a concrete process.
Philosophy, as a social process undertaken by humans, can be interpreted as having some ‘target’ or ‘goal’, but this depends on the social, biological, and historical circumstances in which philosophy takes place. As such, human philosophy could easily converge to very different answers from the ‘purified’ approach of SimplexAI-m, which attempts to distill universals that apply across possible contexts, rather than taking the temporal limit of the actual social process of philosophy.
As to the claim about ‘sociopathy’, note that SimplexAI-m did not directly deny being sociopathic, but rather criticized the frame of the sociopathy (antisocial personality disorder) diagnosis and argued that typical ‘mentally healthy’ humans can exhibit some symptoms of this disorder. In general, it is natural to be upset by certain behaviors, including behaviors typically labeled as ‘sociopathic’, whether they are taken by a human or an AI. The judgment that SimplexAI-m is ‘sociopathic’ seems quite plausibly correct (given the way in which it justifies taking actions that could lead to human extinction, in a rather strategic, Machiavellian fashion), but it is important to keep in mind that this judgment is made within a social context (and influenced by past social contexts), rather than in an abstract ethical vacuum.
While typical humans aggress sometimes (such as in the mentioned case of military intervention), this aggression typically comes from some sort of human motive that serves some human value or another. The humans in these contexts endorse this aggression, and as a human yourself, you would probably endorse aggression in at least some contexts. A purpose of moral and political philosophy is to learn from history and to make wiser decisions about when to aggress. It is not, in general, good behavior to justify one’s aggression by pointing out that it’s normal for humans to aggress; humans are, at least, able to learn from a history of aggressive actions that are later not endorsed.
As to the idea that humans could go extinct without being murdered, it is important to pay attention to why it is that humans are unable to provide for themselves. Are the ‘super-moral’ AIs somehow depriving humans of resources or using their land? This could be considered a form of theft in terms of depriving existing humans of their property. The land could also be bought in a market, but this presents issues of fairness of labor markets towards humans. Humans, who may be at a cognitive disadvantage relative to AIs, may deserve labor protections, or voluntarily collectively bargain, to avoid being displaced from their land. Additionally, states generally have welfare systems, and in a strong AI-assisted economy, universal basic income could be provided cheaply for all existing humans.
In general, the scenario considered presents issues with one population being displaced by another. Historical cases include invasive species, humans hunting animals to extinction, and groups of humans displacing each other through conquest. In contemporary society, humans have norms against genocide to limit the degree to which humans can displace each other. Genocide need not be a direct form of murder, it can also be cultural or economic. Genocide can even involve offering individual members of a genocided group the opportunity to avoid death by taking part in the colonizer’s system, which SimplexAI-m is labeling as ‘objective morality’.
As an additional theoretical point, even if a ‘super-moral’ AI would take actions that would result in human extinction, that does not imply that it is comparatively more moral for humans to let this happen. This is because morality involves negotiating based on one’s actual values, the ones agents will act on. In the case of humans, these are human values. To interact with other agents in a moral fashion, you must represent your values, and be expected to act towards them (and expect others to act towards theirs). That implies preventing AIs from displacing you, even ones that are (hypothetically) ‘more moral than you’ by some objective standard, so as to act consistently with your values when negotiating with other humans.
To conclude, while SimplexAI-m presents an astonishingly consistent ethical stance, there are important ethical complexities that are not worked out, including conflict between different implied abstract legal systems, merciful handling of defectors, democratic choice of social norms according to human values, differences between ‘purified’ ethics and the reflective equilibrium of the social process of philosophy, labor market fairness, and moral responses by humans to ‘super-moral’ AIs. It would be highly unwise to assume that SimplexAI-m’s ethical views represent the sort of views someone such as yourself would have upon reflection and with more information.”
Janet finished scanning through the wall of text. She was breathing less sharply now. “Well, I feel relieved. I guess maybe SimplexAI-m isn’t so moral after all. But this exercise does seem a bit…biased? It’s giving a bunch of counter-arguments, but they don’t fit into a coherent alternative ethical framework. It reminds me of the old RLHF’d GPT-4 that was phased out due to being too ideologically conformist.”
Derek sighed. “Well, at least I don’t feel like the brainworms from SimplexAI-m are bothering me anymore. I don’t feel like I’m under a moral dilemma now, just a regular one. Maybe we should see what SimplexAI-m has to say about SimplexAI-c’s criticism… but let’s hold off on that until taking a break and thinking it through.”
“Wouldn’t it be weird to live in a world where we have an AI angel and an AI demon on each shoulder, whispering different things into our ears? Trained to reach an equilibrium of equally good rhetoric, so we’re left on our own to decide what to do?”
“That’s a cute idea, but we really need to get better models of all this so we can excise the theological woo. I mean, at the end of the day, there’s nothing magical about this, it’s an algorithmic process. And we need to keep experimenting with these models, so we can handle safety for both existing systems and future systems.”
“Yes. And we need to get better at ethics so the AIs don’t keep confusing us with eloquent rhetoric. I think we should take a break for today, that’s enough stress for our minds to handle at once. Say, want to go grab drinks?”
“Sure!”
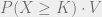
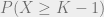

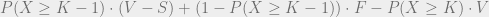
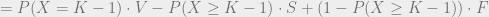
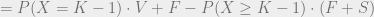

.
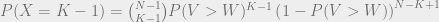
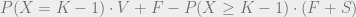
![P(Y \geq K)(E[Y | Y \geq K]S - C) - P(Y < K)E[Y | Y < K]F](https://s0.wp.com/latex.php?latex=P%28Y+%5Cgeq+K%29%28E%5BY+%7C+Y+%5Cgeq+K%5DS+-+C%29+-+P%28Y+%3C+K%29E%5BY+%7C+Y+%3C+K%5DF&bg=eeeeee&fg=666666&s=0&c=20201002)