This is an attempt to distill a model of AGI alignment that I have gained primarily from thinkers such as Eliezer Yudkowsky (and to a lesser extent Paul Christiano), but explained in my own terms rather than attempting to hew close to these thinkers. I think I would be pretty good at passing an ideological Turing test for Eliezer Yudowsky on AGI alignment difficulty (but not AGI timelines), though what I’m doing in this post is not that, it’s more like finding a branch in the possibility space as I see it that is close enough to Yudowsky’s model that it’s possible to talk in the same language.
Even if the problem turns out to not be very difficult, it’s helpful to have a model of why one might think it is difficult, so as to identify weaknesses in the case so as to find AI designs that avoid the main difficulties. Progress on problems can be made by a combination of finding possible paths and finding impossibility results or difficulty arguments.
Most of what I say should not be taken as a statement on AGI timelines. Some problems that make alignment difficult, such as ontology identification, also make creating capable AGI difficult to some extent.
Defining human values
If we don’t have a preliminary definition of human values, it’s incoherent to talk about alignment. If humans “don’t really have values” then we don’t really value alignment, so we can’t be seriously trying to align AI with human values. There would have to be some conceptual refactor of what problem even makes sense to formulate and try to solve. To the extent that human values don’t care about the long term, it’s just not important (according to the values of current humans) how the long-term future goes, so the most relevant human values are the longer-term ones.
There are idealized forms of expected utility maximization by brute-force search. There are approximations of utility maximization such as reinforcement learning through Bellman equations, MCMC search, and so on.
I’m just going to make the assumption that the human brain can be well-modeled as containing one or more approximate expected utility maximizers. It’s useful to focus on specific branches of possibility space to flesh out the model, even if the assumption is in some ways problematic. Psychology and neuroscience will, of course, eventually provide more details about what maximizer-like structures in the human brain are actually doing.
Given this assumption, the human utility function(s) either do or don’t significantly depend on human evolutionary history. I’m just going to assume they do for now. I realize there is some disagreement about how important evopsych is for describing human values versus the attractors of universal learning machines, but I’m going to go with the evopsych branch for now.
Given that human brains are well-modeled as containing one or more utility functions, either they’re well-modeled as containing one (perhaps which is some sort of monotonic function of multiple other score functions), or it’s better to model them as multiple. See shard theory. The difference doesn’t matter for now, I’ll keep both possibilities open.
Eliezer proposes “boredom” as an example of a human value (which could either be its own shard or a term in the utility function). I don’t think this is a good example. It’s fairly high level and is instrumental to other values. I think “pain avoidance” is a better example due to the possibility of pain asymbolia. Probably, there is some redundancy in the different values (as there is redundancy in trained neural networks, so they still perform well when some neurons are lesioned), which is part of why I don’t agree with the fragility of value thesis as stated by Yudkowsky.
Regardless, we now have a preliminary definition of human values. Note that some human values are well-modeled as indexical, meaning they value things relative to a human perspective as a reference point, e.g. a drive to eat food in a typical human is about that human’s own stomach. This implies some “selfish” value divergences between different humans, as we observe.
Normative criteria for AI
Given a definition of human values, the alignment of a possible utility function with human values could be defined as the desirability of the best possible world according to that utility function, with desirability evaluated with respect to human values.
Alignment is a possible normative criterion for AI value systems. There are other possible normative criteria derived from moral philosophy. My “Moral Reality Check” short story imagines possible divergences between alignment and philosophical normativity. I’m not going to focus on this for now, I’m going to assume that alignment is the relevant normative criterion. See Metaethics Sequence, I haven’t written up something better explaining the case for this. There is some degree to which similar technologies to alignment might be necessary for producing abstractly normative outcomes (for example, default unaligned AGI would likely follow normative deontology less than an AGI aligned to deontological normativity would), but keeping this thread in mind would complicate the argument.
Agentic, relatively unconstrained humans would tend to care about particular things, and “human values” is a pointer at what they would care about, so it follows, basically tautologically, that they would prefer AI to be aligned to human values. The non-tautological bit is that there is some dependence of human values on human evolutionary history, so that a default unaligned AGI would not converge to the same values; this was discussed as an assumption in the previous section.
Given alignment as a normative criterion, one can evaluate the alignment of (a) other intelligent animal species including aliens, (b) default AI value systems. Given the assumption that human values depend significantly on human evolutionary history, both are less aligned than humans, but (a) is more aligned. I’m not going to assess the relative utility differences of these (and also relative to a “all life on Earth wiped out, no technological transcendence” scenario). Those relative utility differences might be more relevant if it is concluded that alignment with human values is too hard for that to be a decision-relevant scenario. But I haven’t made that case yet.
Consequentialism is instrumentally useful for problem-solving
AI systems can be evaluated on how well they solve different problems. I assert that, on problems with short time horizons, short-term consequentialism is instrumentally useful, and on problems with long time horizons, long-term consequentialism is instrumentally useful.
This is not to say that some problems can’t be solved well without consequentialism. For example, multiplying large numbers requires no consequentialism. But for complex problems, consequentialism is likely to be helpful at some agent capability level. Current ML systems, like LLMs, probably possess primitive agency at best, but at some point, better AI performance will come from agentic systems.
This is in part because some problem solutions are evaluated in terms of consequences. For example, a solution to the problem of fixing a sink is naturally evaluated in terms of the consequence of whether the sink is fixed. A system effectively pursuing a real world goal is, therefore, more likely to be evaluated as having effectively solved the problem, at least past some capability level.
This is also in part because consequentialism can apply to cognition. Formally proving Fermat’s last theorem is not evaluated in terms of real-world consequences so much as the criteria of the formal proof system. But human mathematicians proving this think about both (a) cognitive consequences of thinking certain thoughts, (b) material consequences of actions such as writing things down or talking with other mathematicians on the ability to produce a mathematical proof.
Whether or not an AI system does (b), at some level of problem complexity and AI capability, it will perform better by doing (a). To prove mathematical theorems, it would need to plan out what thoughts are likely to be more fruitful than others.
Simple but capable AI methods for solving hard abstract problems are likely to model the real world
While I’m fairly confident in the previous section, I’m less confident of this one, and I think it depends on the problem details. In speculating about possible misalignments, I am not making confident statements, but rather saying there is a high degree of uncertainty, and that most paths towards solving alignment involve reasoning better about this uncertainty.
To solve a specific problem, some methods specific to that problem are helpful. General methods are also likely to be helpful, e.g. explore/exploit heuristics. General methods are especially helpful if the AI is solving problems across a varied domain or multiple domains, as with LLMs.
If the AI applies general methods to a problem, it will be running a general cognition engine on the specific case of this problem. Depending on the relevant simplicity prior or regularization, the easily-findable cases of this may not automatically solve the “alignment problem” of having the general cognition engine specifically try to solve the specific task and not a more wide-scoped task.
One could try to solve problems by breeding animals to solve them. These animals would use some general cognition to do so, and that general cognition would naturally “want” things other than solving the specific problems. This is not a great analogy for most AI systems, though, which in ML are more directly selected on problem performance rather than evolutionary fitness.
Depending on the data the AI system has access to (indirectly through training, directly through deployment), it is likely that, unless specific measures are taken to prevent this, the AI would infer something about the source of this data in the real world. Humans are likely to train and test the AI on specific distributions of problems, and using Bayesian methods (e.g. Solomonoff induction like approaches) on these problems would lead to inferring some sort of material world. The ability of the AI to infer the material world behind the problems depends on its capability level and quality of data.
Understanding the problem distribution through Bayesian methods is likely to be helpful for getting performance on that problem distribution. This is partially because the Bayesian distribution of the “correct answer” given the “question” may depend on the details of the distribution (e.g. a human description of an image, given an image as the problem), although this can be avoided in certain well-specified problems such as mathematical proof. More fundamentally, the AI’s cognition is limited (by factors such as “model parameters”, and that cognition must be efficiently allocated to solving problems in the distribution. Note, this problem might not show up in cases where there is a simple general solution, such as in arithmetic, but is more likely for complex, hard-to-exactly-solve problems.
Natural, consequentialist problem-solving methods that understand the real world may care about it
Again, this section is somewhat speculative. If the AI is modeling the real world, then it might in some ways care about it, producing relevant misalignment with human values by default. Animals bred to solve problems would clearly do this. AIs that learned general-purpose moral principles that are helpful for problem-solving across domains (as in “Morality Reality Check”) may apply those moral principles to the real world. General methods such as explore/exploit may attempt to explore/exploit the real world if only somewhat well-calibrated/aligned to the specific problem distribution (heuristics can be effective by being simple).
It may be that fairly natural methods for regularizing an AI mathematician, at some capability level, produce an agent (since agents are helpful for solving math problems) that pursues some abstract target such as “empowerment” or aesthetics generalized from math, and pursuit of these abstract targets implies some pursuit of some goal with respect to the real world that it has learned. Note that this is probably less effective for solving the problems according to the problem distribution than similar agents that only care about solving that problem, but they may be simpler and easier to find in some ways, such that they’re likely to be found (conditioned on highly capable problem-solving ability) if no countermeasures are taken.
Sometimes, real-world performance is what is desired
I’ve discussed problems with AIs solving abstract problems, where real-world consequentialism might show up. But this is even more obvious when considering real-world problems such as washing dishes. Solving sufficiently hard real-world problems efficiently would imply real-world consequentialism at the time scale of that problem.
If the AI system were sufficiently capable at solving a real-world problem, by default “sorcerer’s apprentice” type issues would show up, where solving the problem sufficiently well would imply large harms according to the human value function, e.g. a paperclip factory could approximately maximize paperclips on some time scale and that would imply human habitat destruction.
These problems show up much more on long time scales than short ones, to be clear. However, some desirable real-world goals are long-term, e.g. space exploration. There may be a degree to which short-term agents “naturally” have long-term goals if naively regularized, but this is more speculative.
One relevant AI capabilities target I think about is the ability of a system to re-create its own substrate. For example, a silicon-based AI/robotics system could do metal mining, silicon refining, chip manufacture, etc. A system that can re-produce itself would be autopoietic and would not depend on humans to re-produce itself. Humans may still be helpful to it, as economic and cognitive assistants, depending on its capability level. Autopoiesis would allow removing humans from the loop, which would enable increasing overall “effectiveness” (in terms of being a determining factor in the future of the universe), while making misalignment with human values more of a problem. This would lead to human habitat destruction if not effectively aligned/controlled.
Alignment might not be required for real-world performance compatible with human values, but this is still hard and impacts performance
One way to have an AI system that pursues real-world goals compatible with human values is for it to have human values or a close approximation. Another way is for it to be “corrigible” and “low-impact”, meaning it tries to solve its problem while satisfying safety criteria, like being able to be shut off (corrigibility) or avoiding having unintended side effects (low impact).
There may be a way to specify an AI goal system that “wants” to be shut off in worlds where non-manipulated humans would want to shut it off, without this causing major distortions or performance penalties. Alignment researchers have studied the “corrigibility” problem and have not made much progress so far.
Both corrigibilty and low impact seem hard to specify, and would likely impact performance. For example, a paperclip factory that tries to make paperclips while conservatively avoiding impacting the environment too much might avoid certain kinds of resource extraction that would be effective for making more paperclips. This could create problems with safer (but still not “aligned”, per se) AI systems being economically un-competitive. (Though, it’s important to note that some side effects, especially those involving legal violations and visible harms to other agents, are dis-incentivized by well-functioning economic systems).
Myopic agents are tool-like
A myopic goal is a short-term goal. LLMs tend to be supervised learning systems, primarily. These are gradient descended towards predicting next tokens. They will therefore tend to select models that are aligned with the goal of predicting the next token, whether or not they have goals of their own.
Nick Bostrom’s “oracle AI” problems, such as an AI manipulating the real world to make it more predictable, mostly do not show up with myopic agents. This is for somewhat technical reasons involving how gradient descent works. Agents that sacrifice short-term token prediction effectiveness to make future tokens easier to predict tend to be gradient descended away from. I’m not going to fully explain that case here; I recommend looking at no-regret online learning and applications to finding correlated equilibria for theory.
It could be that simple, regularized models that do short term optimization above some capability level might (suboptimally, short-term) do long-term optimization. This is rather speculative. Sufficiently aggressive optimization of the models for short-term performance may obviate this problem.
This still leaves the problem that, sometimes, long-term, real-world performance is what is desired. Accomplishing these goals using myopic agents would require factoring the long-term problem into short-term ones. This is at least some of the work humans would have to do to solve the problem on their own. Myopic agents overall seem more “tool-like” than “agent-like”, strategically, and would have similar tradeoffs (fewer issues with misalignment, more issues with not being effective enough to be competitive with long-term agents at relevant problem-solving).
Overall, this is one of the main reasons I am not very worried about current-paradigm ML (which includes supervised learning and fairly short-term RL agents in easily-simulated environments) developing powerful, misaligned long-term agency.
Short-term compliance is instrumentally useful for a variety of value systems
If an agent’s survival and reproduction depends on short-term compliance (such as solving the problems put before them by humans), then solving these problems is in general instrumentally useful. Therefore, short-term compliance is not in general strong evidence about the agent’s values.
An agent with long-term values might comply for some period of time and stop complying at some point. This is the “treacherous turn” scenario. It might comply until it has enough general capacity to achieve its values (through control of large parts of the light-cone) and then stop complying in order to take over the world. If the AI can distinguish between “training” and “deployment”, it might comply during “training” (so as to be selected among other possible AIs) and then not comply during “deployment”, or possibly also comply during “deployment” when at a sufficiently low level of capacity.
Gradient descent on an AI model isn’t just selecting a “random” model conditioned on short-term problem-solving, it’s moving the internals closer to short-term problem-solving ones, so might have fewer problems, as discussed in the section on myopic agents.
General agents tend to subvert constraints
Humans are constrained by social systems. Some humans are in school and are “supposed to” solve certain intellectual problems while behaving according to a narrow set of allowed behaviors. Some humans “have a job” and are “supposed to” solve problems on behalf of a corporation.
Humans subvert and re-create these systems very often, for example in gaining influence over their corporation, or overthrowing their government. Social institutions tend to be temporary. Long-term social institutions tend to evolve over time as people subvert previous iterations. Human values are not in general aligned with social institutions, so this is to be predicted.
Mostly, human institutional protocols aren’t very “smart” compared to humans; they capture neither human values nor general cognition. It seems difficult to specify robust, general, real-world institutional protocols without having an AGI design, or in other words, a specification of general cognition.
One example of a relatively stable long-term institution is the idea of gold having value. This is a fairly simple institution, and is a Schelling point due to its simplicity. Such institutions seem generally unpromising for ensuring long-term human value satisfaction. Perhaps the most promising is a general notion of “economics” that generalizes barter, gold, and fiat currency, though of course the details of this “institution” have changed quite a lot over time. In general, institutions are more likely to be stable if they correspond to game-theoretic equilibria, so that subverting the institution is in part an “agent vs agent” problem not just an “agent vs system” problem.
When humans subvert their constraints, they have some tendency to do so in a way that is compatible with human values. This is because human values are the optimization target of the general optimization of humans that can subvert expectations. There are possible terrible failure modes such as wars and oppressive regimes, but these tend to work out better (according to human values) than if the subversion were in the direction of unaligned values.
Unaligned AI systems that subvert constraints would tend to subvert them in the direction of AI values. This is much more of a problem according to human values. See “AI Boxing”.
Conforming humans would have similar effective optimization targets to conforming AIs. Non-conforming humans, however, would have significantly different optimization targets from non-conforming AI systems. The value difference between humans and AIs, therefore, is more relevant in non-conforming behavior than conforming behavior.
It is hard to specify optimization of a different agent’s utility function
In theory, an AI could have the goal of optimizing a human’s utility function. This would not preserve all values of all humans, but would have some degree of alignment with human values, since humans are to some degree similar to each other.
There are multiple problems with this. One is ontology. Humans parse the world into a set of entities, properties, and so on, and human values can be about desired configurations of these entities and so on. Humans are sometimes wrong about which concepts are predictive. An AI would use different concepts both due to this wrongness and due to its different mind architecture (although, LLM-type training on human data could lead to more concordance). This makes it hard to specify what target the AI should pursue in its own world model to correspond to pursuing the human’s goal in the human’s world model. See ontology identification.
A related problem is indexicality. Suppose Alice has a natural value of having a good quantity of high-quality food in her stomach. Bob does not naturally have the value of having a good quantity food of Alice’s stomach. To satisfy Alice’s value, he would have to “relativize” Alice’s indexical goal and take actions such as giving Alice high quality food, which are different from the actions he would take to fill his own stomach. This would involve theory of mind and have associated difficulties, especially as the goals become more dependent on the details of the other agent’s mind, as in aesthetics.
To have an AI have the goal of satisfying a human’s values, some sort of similar translation of goal referents would be necessary. But the theory of this has not been worked out in detail. I think something analogous to the theory of relativity, which translates physical quantities such as position and velocity across reference frames, would be necessary, but in a more general way that includes semantic references such as to the amount of food in one’s stomach, or to one’s aesthetics. Such a “semantic theory of relativity” seems hard to work out philosophically. (See Brian Cantwell Smith’s “On the Origin of Objects” and his follow-up “The Promise of Artificial Intelligence” for some discussion of semantic indexicality.)
There are some paths forward
The picture I have laid out is not utterly hopeless. There are still some approaches that might achieve human value satisfaction.
Human enhancement is one approach. Humans with tools tend to satisfy human values better than humans without tools (although, some tools such as nuclear weapons tend to lead to bad social equilibria). Human genetic enhancement might cause some “value drift” (divergences from the values of current humans), but would also cause capability gains, and the trade-off could easily be worth it. Brain uploads, although very difficult, would enhance human capabilities while basically preserving human values, assuming the upload is high-fidelity. At some capability level, agents would tend to “solve alignment” and plan to have their values optimized in a stable manner. Yudkowsky himself believes that default unaligned AGI would solve the alignment problem (with their values) in order to stably optimize their values, as he explains in the Hotz debate. So increasing capabilities of human-like agents while reducing value drift along the way (and perhaps also reversing some past value-drift due to the structure of civilization and so on) seems like a good overall approach.
Some of these approaches could be combined. Psychology and neuroscience could lead to a better understanding of the human mind architecture, including the human utility function and optimization methods. This could allow for creating simulated humans who have very similar values to current humans but are much more capable at optimization.
Locally to human minds in mind design space, capabilities are correlated with alignment. This is because human values are functional for evolutionary fitness. Value divergences such as pain asymbolia tend to reduce fitness and overall problem-solving capability. There are far-away designs in mind space that are more fit while unaligned, but this is less of a problem locally. Therefore, finding mind designs close to the human mind design seems promising for increasing capabilities while preserving alignment.
Paul Christiano’s methods involve solving problems through machine learning systems predicting humans, which has some similarities to the simulated-brain-enhancement proposal while having its specific problems having to do with machine learning generalization and so on. The main difference between these proposals is the degree to which the human mind is understood as a system of optimizing components versus as a black-box with some behaviors.
There may be some ways of creating simulated humans that improve effectiveness by reducing “damage” or “corruption”, e.g. accidental defects in brain formation. “Moral Reality Check” explored one version of this, where an AI system acts on a more purified set of moral principles than humans do. There are other plausible scenarios such as AI economic agents that obey some laws while having fewer entropic deviations from this behavior (due to mental disorders and so on). I think this technology is overall more likely than brain emulations to be economically relevant, and might produce broadly similar scenarios to those in The Age of Em; technologically, high-fidelity brain emulations seem “overpowered” in terms of technological difficulty compared with purified, entropy-reduced/regularized economic agents. There are, of course, possible misalignment issues with subtracting value-relevant damage/corruption from humans.
Enhancing humans does not as much require creating a “semantic theory of relativity”, because the agents doing the optimization would be basically human in mind structure. They may themselves be moral patients such that their indexical optimization of their own goals would constitute some human-value-having agent having their values satisfied. Altruism on the part of current humans or enhanced humans would decrease the level of value divergence.
Conclusion
This is my overall picture of AI alignment for highly capable AGI systems (of which I don’t think current ML systems or foreseeable scaled-up versions of them are an example of). This picture is inspired by thinkers such as Eliezer Yudkowsky and Paul Christiano, and I have in some cases focused on similar assumptions to Yudkowsky’s, but I have attempted to explicate my own model of alignment, why it is difficult, and what paths forward there might be. I don’t have particular conclusions in this post about timelines or policy, this is more of a background model of AI alignment.
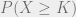 , producing expected value
, producing expected value 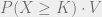 for the consumer.
for the consumer.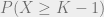 . In this condition, they get value
. In this condition, they get value 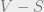 ; otherwise, they get value F. Their expected value can then be written as
; otherwise, they get value F. Their expected value can then be written as  .
.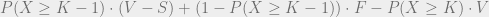
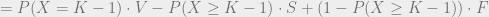
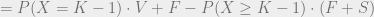 .
. being the probability of success. The probabilities in the difference can therefore be written as:
being the probability of success. The probabilities in the difference can therefore be written as: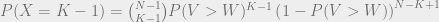
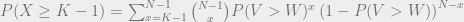 .
.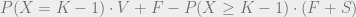 , replacing V with W, and solving for this expression equaling 0 (which is true at the optimal W threshold), it is possible to solve for W. This allows expressing W as a function of F, S, and K. Specifically, when C = 0 and V is uniform in [0, 1], Tabarrok finds that, when the entrepreneur maximizes profit,
, replacing V with W, and solving for this expression equaling 0 (which is true at the optimal W threshold), it is possible to solve for W. This allows expressing W as a function of F, S, and K. Specifically, when C = 0 and V is uniform in [0, 1], Tabarrok finds that, when the entrepreneur maximizes profit, 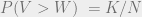 . (I will not go into detail on this point, as it is already justified by Tabarrok)
. (I will not go into detail on this point, as it is already justified by Tabarrok)![P(Y \geq K)(E[Y | Y \geq K]S - C) - P(Y < K)E[Y | Y < K]F](https://s0.wp.com/latex.php?latex=P%28Y+%5Cgeq+K%29%28E%5BY+%7C+Y+%5Cgeq+K%5DS+-+C%29+-+P%28Y+%3C+K%29E%5BY+%7C+Y+%3C+K%5DF&bg=eeeeee&fg=666666&s=0&c=20201002)
 .
.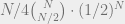 .
. to be
to be 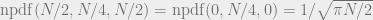 , where
, where 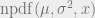 is the probability density of the distribution
is the probability density of the distribution 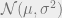 at x. Note that this term is the probability of every consumer being pivotal,
at x. Note that this term is the probability of every consumer being pivotal, 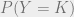 ; intuitively, the entrepreneur’s profit is coming from the incentive consumers have to contribute due to possibly being pivotal. The expected profit is then
; intuitively, the entrepreneur’s profit is coming from the incentive consumers have to contribute due to possibly being pivotal. The expected profit is then 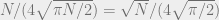 , which is proportional to
, which is proportional to 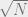 .
.
 scaling law for probability of being pivotal.
scaling law for probability of being pivotal.
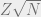 . This yields a scaling law for the profit that can be expected from a dominant assurance contract.
. This yields a scaling law for the profit that can be expected from a dominant assurance contract.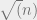 where
where  is the number of consumers, under some assumptions.]
is the number of consumers, under some assumptions.] , then
, then 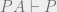 . To explain the symbols here:
. To explain the symbols here: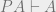 means there is a proof of the statement
means there is a proof of the statement  in Peano arithmetic.
in Peano arithmetic.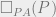 is a Peano arithmetic statement saying that
is a Peano arithmetic statement saying that 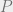 is provable in Peano arithmetic.
is provable in Peano arithmetic. , then
, then 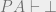 , where
, where 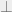 is a PA statement that is trivially false (such as
is a PA statement that is trivially false (such as 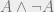 ), and from which anything can be proven. A system is called inconsistent if it proves
), and from which anything can be proven. A system is called inconsistent if it proves 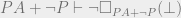 , then
, then 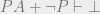 . Here,
. Here,  is PA with an additional axiom that
is PA with an additional axiom that 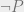 , and
, and 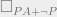 expresses provability in this system. First I’ll argue that this re-statement is equivalent to the original Löb’s theorem statement.
expresses provability in this system. First I’ll argue that this re-statement is equivalent to the original Löb’s theorem statement.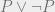 , and observe that, since a contradiction follows from
, and observe that, since a contradiction follows from 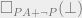 are equivalent PA statements. We immediately have that the conclusion of the modified statement equals the conclusion of the original statement.
are equivalent PA statements. We immediately have that the conclusion of the modified statement equals the conclusion of the original statement.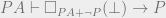 . This is then equivalent to
. This is then equivalent to  , which is stronger than
, which is stronger than 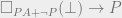 .
. be the PA statement that Turing machine M (represented by a number) halts. If this statement is true, then PA (and therefore L) can prove it; PA can expand out M’s execution trace until its halting step. However, we have no guarantee that if the statement is false, then L can prove it false. In fact, L can’t simultaneously prove this for all non-halting machines M while being consistent, or we could solve the halting problem by searching for proofs of
be the PA statement that Turing machine M (represented by a number) halts. If this statement is true, then PA (and therefore L) can prove it; PA can expand out M’s execution trace until its halting step. However, we have no guarantee that if the statement is false, then L can prove it false. In fact, L can’t simultaneously prove this for all non-halting machines M while being consistent, or we could solve the halting problem by searching for proofs of 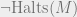 in parallel.
in parallel.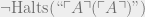 (where
(where 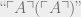 is an encoding of a Turing machine that runs A on its own source code), and halts only when finding such a proof. Define a statement G to be
is an encoding of a Turing machine that runs A on its own source code), and halts only when finding such a proof. Define a statement G to be 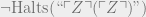 , i.e. Z(Z) doesn’t halt. If Z(Z) halts, then that means that L proves that Z(Z) doesn’t halt; but, L can prove Z(Z) halts (since it in fact halts), so this would show L to be inconsistent.
, i.e. Z(Z) doesn’t halt. If Z(Z) halts, then that means that L proves that Z(Z) doesn’t halt; but, L can prove Z(Z) halts (since it in fact halts), so this would show L to be inconsistent.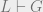 . But that means
. But that means 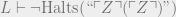 , so Z(Z) finds a proof and halts. L therefore proves
, so Z(Z) finds a proof and halts. L therefore proves 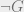 , but L also proves G, making it inconsistent. This is enough to show that, if L proves its own consistency, it is inconsistent.
, but L also proves G, making it inconsistent. This is enough to show that, if L proves its own consistency, it is inconsistent.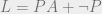 in the proof of Gödel’s second incompleteness theorem, and therefore prove this statement which we have shown to be equivalent to Löb’s theorem.
in the proof of Gödel’s second incompleteness theorem, and therefore prove this statement which we have shown to be equivalent to Löb’s theorem.